How many of you have never encountered a crash or a failure of your systems in production environment? Certainly, each one of you, sooner or later, has experienced it. If we are not able to avoid a failure, the solution seems to be maintaining our system in the state of permanent failure. This concept underpins the tool invented by Netflix to test the resilience of its IT infrastructure – Chaos Monkey. A few days ago I came across the solution, based on the idea behind Netflix’s tool, designed to test Spring Boot applications. Such a library has been implemented by Codecentric. Until now, I recognize them only as the authors of other interesting solution dedicated for Spring Boot ecosystem – Spring Boot Admin. I have already described this library in one of my previous articles Monitoring Microservices With Spring Boot Admin (https://piotrminkowski.wordpress.com/2017/06/26/monitoring-microservices-with-spring-boot-admin).
Today I’m going to show you how to include Codecentric’s Chaos Monkey in your Spring Boot application, and then implement chaos engineering in sample system consists of some microservices. The Chaos Monkey library can be used together with Spring Boot 2.0, and the current release version of it is 1.0.1. However, I’ll implement the sample using version 2.0.0-SNAPSHOT, because it has some new interesting features not available in earlier versions of this library. In order to be able to download SNAPSHOT version of Codecentric’s Chaos Monkey library you have to remember about including Maven repository https://oss.sonatype.org/content/repositories/snapshots to your repositories in pom.xml.
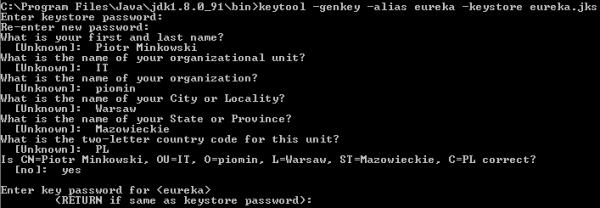
1. Enable Chaos Monkey for an application
There are two required steps for enabling Chaos Monkey for Spring Boot application. First, let’s add library chaos-monkey-spring-boot to the project’s dependencies.
<dependency> <groupId>de.codecentric</groupId> <artifactId>chaos-monkey-spring-boot</artifactId> <version>2.0.0-SNAPSHOT</version> </dependency>
Then, we should activate profile chaos-monkey on application startup.
$ java -jar target/order-service-1.0-SNAPSHOT.jar --spring.profiles.active=chaos-monkey
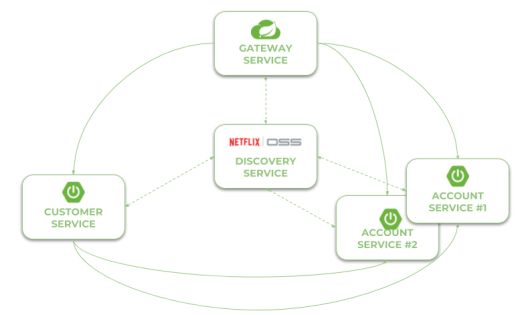
2. Sample system architecture
Our sample system consists of three microservices, each started in two instances, and a service discovery server. Microservices registers themselves against a discovery server, and communicates with each other through HTTP API. Chaos Monkey library is included to every single instance of all running microservices, but not to the discovery server. Here’s the diagram that illustrates the architecture of our sample system.

The source code of sample applications is available on GitHub in repository sample-spring-chaosmonkey (https://github.com/piomin/sample-spring-chaosmonkey.git). After cloning this repository and building it using mnv clean install command, you should first run discovery-service. Then run two instances of every microservice on different ports by setting -Dserver.port property with an appropriate number. Here’s a set of my running commands.
$ java -jar target/discovery-service-1.0-SNAPSHOT.jar $ java -jar target/order-service-1.0-SNAPSHOT.jar --spring.profiles.active=chaos-monkey $ java -jar -Dserver.port=9091 target/order-service-1.0-SNAPSHOT.jar --spring.profiles.active=chaos-monkey $ java -jar target/product-service-1.0-SNAPSHOT.jar --spring.profiles.active=chaos-monkey $ java -jar -Dserver.port=9092 target/product-service-1.0-SNAPSHOT.jar --spring.profiles.active=chaos-monkey $ java -jar target/customer-service-1.0-SNAPSHOT.jar --spring.profiles.active=chaos-monkey $ java -jar -Dserver.port=9093 target/customer-service-1.0-SNAPSHOT.jar --spring.profiles.active=chaos-monkey
3. Process configuration
In version 2.0.0-SNAPSHOT of chaos-monkey-spring-boot library Chaos Monkey is by default enabled for applications that include it. You may disable it using property chaos.monkey.enabled. However, the only assault which is enabled by default is latency. This type of assault adds a random delay to the requests processed by the application in the range determined by properties chaos.monkey.assaults.latencyRangeStart and chaos.monkey.assaults.latencyRangeEnd. The number of attacked requests is dependent of property chaos.monkey.assaults.level, where 1 means each request and 10 means each 10th request. We can also enable exception and appKiller assault for our application. For simplicity, I set the configuration for all the microservices. Let’s take a look on settings provided in application.yml file.
chaos:
monkey:
assaults:
level: 8
latencyRangeStart: 1000
latencyRangeEnd: 10000
exceptionsActive: true
killApplicationActive: true
watcher:
repository: true
restController: true
In theory, the configuration visible above should enable all three available types of assaults. However, if you enable latency and exceptions, killApplication will never happen. Also, if you enable both latency and exceptions, all the requests send to application will be attacked, no matter which level is set with chaos.monkey.assaults.level property. It is important to remember about activating restController watcher, which is disabled by default.
4. Enable Spring Boot Actuator endpoints
Codecentric implements a new feature in the version 2.0 of their Chaos Monkey library – the endpoint for Spring Boot Actuator. To enable it for our applications we have to activate it following actuator convention – by setting property management.endpoint.chaosmonkey.enabled to true. Additionally, beginning from version 2.0 of Spring Boot we have to expose that HTTP endpoint to be available after application startup.
management:
endpoint:
chaosmonkey:
enabled: true
endpoints:
web:
exposure:
include: health,info,chaosmonkey
The chaos-monkey-spring-boot provides several endpoints allowing you to check out and modify configuration. You can use method GET /chaosmonkey to fetch the whole configuration of library. Yo may also disable chaos monkey after starting application by calling method POST /chaosmonkey/disable. The full list of available endpoints is listed here: https://codecentric.github.io/chaos-monkey-spring-boot/2.0.0-SNAPSHOT/#endpoints.
5. Running applications
All the sample microservices stores data in MySQL. So, the first step is to run MySQL database locally using its Docker image. The Docker command visible below also creates database and user with password.
$ docker run -d --name mysql -e MYSQL_DATABASE=chaos -e MYSQL_USER=chaos -e MYSQL_PASSWORD=chaos123 -e MYSQL_ROOT_PASSWORD=123456 -p 33306:3306 mysql
After running all the sample applications, where all microservices are multiplied in two instances listening on different ports, our environment looks like in the figure below.

You will see the following information in your logs during application boot.

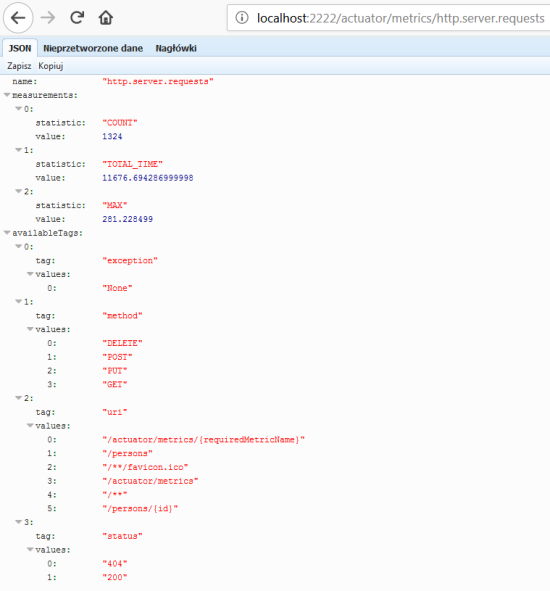
We may check out Chaos Monkey configuration settings for every running instance of application by calling the following actuator endpoint.

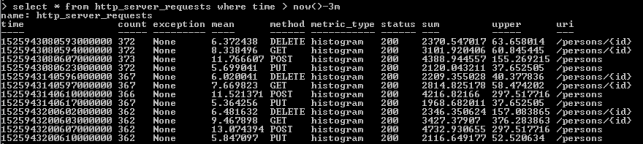
6. Testing the system
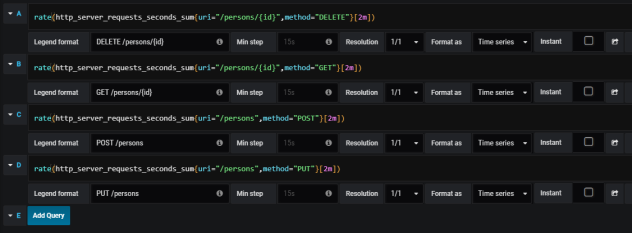
For the testing purposes, I used popular performance testing library – Gatling. It creates 20 simultaneous threads, which calls POST /orders and GET /order/{id} methods exposed by order-service via API gateway 500 times per each thread.
class ApiGatlingSimulationTest extends Simulation {
val scn = scenario("AddAndFindOrders").repeat(500, "n") {
exec(
http("AddOrder-API")
.post("http://localhost:8090/order-service/orders")
.header("Content-Type", "application/json")
.body(StringBody("""{"productId":""" + Random.nextInt(20) + ""","customerId":""" + Random.nextInt(20) + ""","productsCount":1,"price":1000,"status":"NEW"}"""))
.check(status.is(200), jsonPath("$.id").saveAs("orderId"))
).pause(Duration.apply(5, TimeUnit.MILLISECONDS))
.
exec(
http("GetOrder-API")
.get("http://localhost:8090/order-service/orders/${orderId}")
.check(status.is(200))
)
}
setUp(scn.inject(atOnceUsers(20))).maxDuration(FiniteDuration.apply(10, "minutes"))
}
POST endpoint is implemented inside OrderController in add(...) method. It calls find methods exposed by customer-service and product-service using OpenFeign clients. If customer has a sufficient funds and there are still products in stock, it accepts the order and performs changes for customer and product using PUT methods. Here’s the implementation of two methods tested by Gatling performance test.
@RestController
@RequestMapping("/orders")
public class OrderController {
@Autowired
OrderRepository repository;
@Autowired
CustomerClient customerClient;
@Autowired
ProductClient productClient;
@PostMapping
public Order add(@RequestBody Order order) {
Product product = productClient.findById(order.getProductId());
Customer customer = customerClient.findById(order.getCustomerId());
int totalPrice = order.getProductsCount() * product.getPrice();
if (customer != null && customer.getAvailableFunds() >= totalPrice && product.getCount() >= order.getProductsCount()) {
order.setPrice(totalPrice);
order.setStatus(OrderStatus.ACCEPTED);
product.setCount(product.getCount() - order.getProductsCount());
productClient.update(product);
customer.setAvailableFunds(customer.getAvailableFunds() - totalPrice);
customerClient.update(customer);
} else {
order.setStatus(OrderStatus.REJECTED);
}
return repository.save(order);
}
@GetMapping("/{id}")
public Order findById(@PathVariable("id") Integer id) {
Optional order = repository.findById(id);
if (order.isPresent()) {
Order o = order.get();
Product product = productClient.findById(o.getProductId());
o.setProductName(product.getName());
Customer customer = customerClient.findById(o.getCustomerId());
o.setCustomerName(customer.getName());
return o;
} else {
return null;
}
}
// ...
}
Chaos Monkey sets random latency between 1000 and 10000 milliseconds (as shown in the step 3). It is important to change default timeouts for Feign and Ribbon clients before starting a test. I decided to set readTimeout to 5000 milliseconds. It will cause some delayed requests to be timed out, while some will succeeded (around 50%-50%). Here’s timeouts configuration for Feign client.
feign:
client:
config:
default:
connectTimeout: 5000
readTimeout: 5000
hystrix:
enabled: false
Here’s Ribbon client timeouts configuration for API gateway. We have also changed Hystrix settings to disable circuit breaker for Zuul.
ribbon:
ConnectTimeout: 5000
ReadTimeout: 5000
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 15000
fallback:
enabled: false
circuitBreaker:
enabled: false
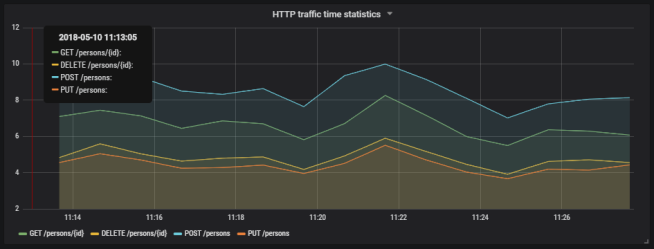
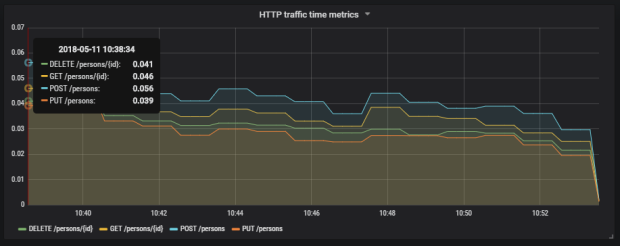
To launch Gatling performance test go to performance-test directory and run gradle loadTest command. Here’s a result generated for the settings latency assaults. Of course, we can change this result by manipulating Chaos Monkey latency values or Ribbon and Feign timeout values.

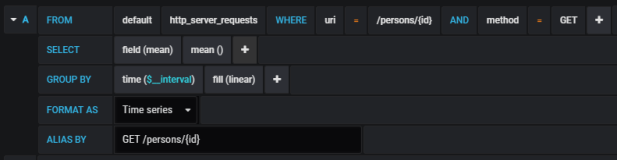
Here’s Gatling graph with average response times. Results do not look good. However, we should remember that a single POST method from order-service calls two methods exposed by product-service and two methods exposed by customer-service.

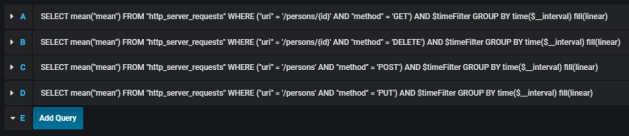
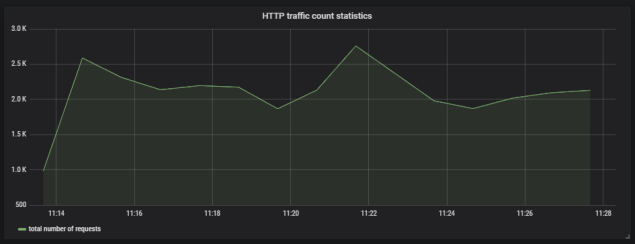
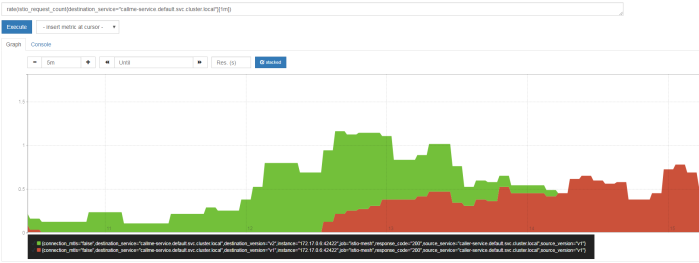
Here’s the next Gatling result graph – this time it illustrates timeline with error and success responses. All HTML reports generated by Gatling during performance test are available under directory performance-test/build/gatling-results