I have already described Spring reactive support about one year ago in the article Reactive microservices with Spring 5. At that time project Spring WebFlux has been under active development, and now after official release of Spring 5 it is worth to take a look on the current version of it. Moreover, we will try to put our reactive microservices inside Spring Cloud ecosystem, which contains such the elements like service discovery with Eureka, load balancing with Spring Cloud Commons @LoadBalanced, and API gateway using Spring Cloud Gateway (also based on WebFlux and Netty). We will also check out Spring reactive support for NoSQL databases by the example of Spring Data Reactive Mongo project.
Here’s the figure that illustrates an architecture of our sample system consisting of two microservices, discovery server, gateway and MongoDB databases. The source code is as usual available on GitHub in sample-spring-cloud-webflux repository.
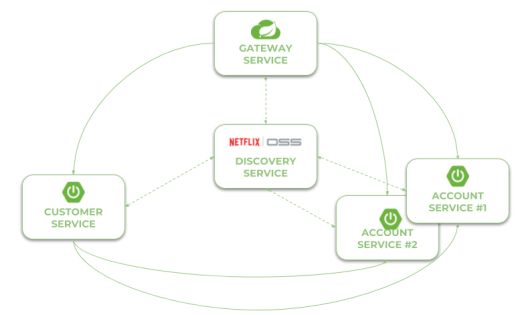
Let’s describe the further steps on the way to create the system illustrated above.
Step 1. Building reactive application using Spring WebFlux
To enable library Spring WebFlux for the project we should include starter spring-boot-starter-webflux to the dependencies. It includes some dependent libraries like Reactor or Netty server.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
REST controller looks pretty similar to the controller defined for synchronous web services. The only difference is in type of returned objects. Instead of single object we return instance of class Mono, and instead of list we return instance of class Flux. Thanks to Spring Data Reactive Mongo we don’t have to do nothing more that call the needed method on the repository bean.
@RestController
public class AccountController {
private static final Logger LOGGER = LoggerFactory.getLogger(AccountController.class);
@Autowired
private AccountRepository repository;
@GetMapping("/customer/{customer}")
public Flux findByCustomer(@PathVariable("customer") String customerId) {
LOGGER.info("findByCustomer: customerId={}", customerId);
return repository.findByCustomerId(customerId);
}
@GetMapping
public Flux findAll() {
LOGGER.info("findAll");
return repository.findAll();
}
@GetMapping("/{id}")
public Mono findById(@PathVariable("id") String id) {
LOGGER.info("findById: id={}", id);
return repository.findById(id);
}
@PostMapping
public Mono create(@RequestBody Account account) {
LOGGER.info("create: {}", account);
return repository.save(account);
}
}
Step 2. Integrate an application with database using Spring Data Reactive Mongo
The implementation of integration between application and database is also very simple. First, we need to include starter spring-boot-starter-data-mongodb-reactive to the project dependencies.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb-reactive</artifactId>
</dependency>
The support for reactive Mongo repositories is automatically enabled after including the starter. The next step is to declare entity with ORM mappings. The following class is also returned as reponse by AccountController.
@Document
public class Account {
@Id
private String id;
private String number;
private String customerId;
private int amount;
...
}
Finally, we may create repository interface that extends ReactiveCrudRepository. It follows the patterns implemented by Spring Data JPA and provides some basic methods for CRUD operations. It also allows to define methods with names, which are automatically mapped to queries. The only difference in comparison with standard Spring Data JPA repositories is in method signatures. The objects are wrapped by Mono and Flux.
public interface AccountRepository extends ReactiveCrudRepository {
Flux findByCustomerId(String customerId);
}
In this example I used Docker container for running MongoDB locally. Because I run Docker on Windows using Docker Toolkit the default address of Docker machine is 192.168.99.100. Here’s the configuration of data source in application.yml file.
spring:
data:
mongodb:
uri: mongodb://192.168.99.100/test
Step 3. Enabling service discovery using Eureka
Integration with Spring Cloud Eureka is pretty the same as for synchronous REST microservices. To enable discovery client we should first include starter spring-cloud-starter-netflix-eureka-client to the project dependencies.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
Then we have to enable it using @EnableDiscoveryClient annotation.
@SpringBootApplication
@EnableDiscoveryClient
public class AccountApplication {
public static void main(String[] args) {
SpringApplication.run(AccountApplication.class, args);
}
}
Microservice will automatically register itself in Eureka. Of cource, we may run more than instance of every service. Here’s the screen illustrating Eureka Dashboard (http://localhost:8761) after running two instances of account-service and a single instance of customer-service. I would not like to go into the details of running application with embedded Eureka server. You may refer to my previous article for details: Quick Guide to Microservices with Spring Boot 2.0, Eureka and Spring Cloud. Eureka server is available as discovery-service module.

Step 4. Inter-service communication between reactive microservices with WebClient
An inter-service communication is realized by the WebClient from Spring WebFlux project. The same as for RestTemplate you should annotate it with Spring Cloud Commons @LoadBalanced . It enables integration with service discovery and load balancing using Netflix OSS Ribbon client. So, the first step is to declare a client builder bean with @LoadBalanced annotation.
@Bean
@LoadBalanced
public WebClient.Builder loadBalancedWebClientBuilder() {
return WebClient.builder();
}
Then we may inject WebClientBuilder into the REST controller. Communication with account-service is implemented inside GET /{id}/with-accounts , where first we are searching for customer entity using reactive Spring Data repository. It returns object Mono , while the WebClient returns Flux . Now, our main goal is to merge those to publishers and return single Mono object with the list of accounts taken from Flux without blocking the stream. The following fragment of code illustrates how I used WebClient to communicate with other microservice, and then merge the response and result from repository to single Mono object. This merge may probably be done in more “ellegant” way, so fell free to create push request with your proposal.
@Autowired
private WebClient.Builder webClientBuilder;
@GetMapping("/{id}/with-accounts")
public Mono findByIdWithAccounts(@PathVariable("id") String id) {
LOGGER.info("findByIdWithAccounts: id={}", id);
Flux accounts = webClientBuilder.build().get().uri("http://account-service/customer/{customer}", id).retrieve().bodyToFlux(Account.class);
return accounts
.collectList()
.map(a -> new Customer(a))
.mergeWith(repository.findById(id))
.collectList()
.map(CustomerMapper::map);
}
Step 5. Building API gateway using Spring Cloud Gateway
Spring Cloud Gateway is one of the newest Spring Cloud project. It is built on top of Spring WebFlux, and thanks to that we may use it as a gateway to our sample system based on reactive microservices. Similar to Spring WebFlux applications it is ran on embedded Netty server. To enable it for Spring Boot application just include the following dependency to your project.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
We should also enable discovery client in order to allow the gateway to fetch list of registered microservices. However, there is no need to register gateway’s application in Eureka. To disable registration you may set property eureka.client.registerWithEureka to false inside application.yml file.
@SpringBootApplication
@EnableDiscoveryClient
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
By default, Spring Cloud Gateway does not enable integration with service discovery. To enable it we should set property spring.cloud.gateway.discovery.locator.enabled to true. Now, the last thing that should be done is the configuration of the routes. Spring Cloud Gateway provides two types of components that may be configured inside routes: filters and predicates. Predicates are used for matching HTTP requests with route, while filters can be used to modify requests and responses before or after sending the downstream request. Here’s the full configuration of gateway. It enables service discovery location, and defines two routes based on entries in service registry. We use the Path Route Predicate factory for matching the incoming requests, and the RewritePath GatewayFilter factory for modifying the requested path to adapt it to the format exposed by the downstream services (endpoints are exposed under path /, while gateway expose them under paths /account and /customer).
spring:
cloud:
gateway:
discovery:
locator:
enabled: true
routes:
- id: account-service
uri: lb://account-service
predicates:
- Path=/account/**
filters:
- RewritePath=/account/(?.*), /$\{path}
- id: customer-service
uri: lb://customer-service
predicates:
- Path=/customer/**
filters:
- RewritePath=/customer/(?.*), /$\{path}
Step 6. Testing the sample system
Before making some tests let’s just recap our sample system. We have two microservices account-service, customer-service that use MongoDB as a database. Microservice customer-service calls endpoint GET /customer/{customer} exposed by account-service. URL of account-service is taken from Eureka. The whole sample system is hidden behind gateway, which is available under address localhost:8090.
Now, the first step is to run MongoDB on Docker container. After executing the following command Mongo is available under address 192.168.99.100:27017.
$ docker run -d --name mongo -p 27017:27017 mongo
Then we may proceeed to running discovery-service. Eureka is available under its default address localhost:8761. You may run it using your IDE or just by executing command java -jar target/discovery-service-1.0-SNAPHOT.jar. The same rule applies to our sample microservices. However, account-service needs to be multiplied in two instances, so you need to override default HTTP port when running second instance using -Dserver.port VM argument, for example java -jar -Dserver.port=2223 target/account-service-1.0-SNAPSHOT.jar. Finally, after running gateway-service we may add some test data.
$ curl --header "Content-Type: application/json" --request POST --data '{"firstName": "John","lastName": "Scott","age": 30}' http://localhost:8090/customer
{"id": "5aec1debfa656c0b38b952b4","firstName": "John","lastName": "Scott","age": 30,"accounts": null}
$ curl --header "Content-Type: application/json" --request POST --data '{"number": "1234567890","amount": 5000,"customerId": "5aec1debfa656c0b38b952b4"}' http://localhost:8090/account
{"id": "5aec1e86fa656c11d4c655fb","number": "1234567892","customerId": "5aec1debfa656c0b38b952b4","amount": 5000}
$ curl --header "Content-Type: application/json" --request POST --data '{"number": "1234567891","amount": 12000,"customerId": "5aec1debfa656c0b38b952b4"}' http://localhost:8090/account
{"id": "5aec1e91fa656c11d4c655fc","number": "1234567892","customerId": "5aec1debfa656c0b38b952b4","amount": 12000}
$ curl --header "Content-Type: application/json" --request POST --data '{"number": "1234567892","amount": 2000,"customerId": "5aec1debfa656c0b38b952b4"}' http://localhost:8090/account
{"id": "5aec1e99fa656c11d4c655fd","number": "1234567892","customerId": "5aec1debfa656c0b38b952b4","amount": 2000}
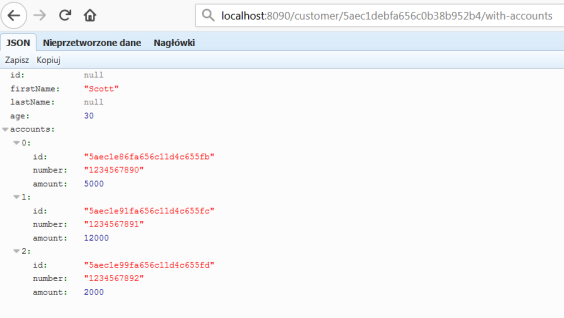
To test inter-service communication just call endpoint GET /customer/{id}/with-accounts on gateway-service. It forward the request to customer-service, and then customer-service calls enpoint exposed by account-service using reactive WebClient. The result is visible below.
Conclusion
Since Spring 5 and Spring Boot 2.0 there is a full range of available ways to build microservices-based architecture. We can build standard synchronous system using one-to-one communication with Spring Cloud Netflix project, messaging microservices based on message broker and publish/subscribe communication model with Spring Cloud Stream, and finally asynchronous, reactive microservices with Spring WebFlux. The main goal of this article is to show you how to use Spring WebFlux together with Spring Cloud projects in order to provide such a mechanisms like service discovery, load balancing or API gateway for reactive microservices build on top of Spring Boot. Before Spring 5 the lack of support for reactive microservices was one of the drawback of Spring framework, but now with Spring WebFlux it is no longer the case. Not only that, we may leverage Spring reactive support for the most popular NoSQL databases like MongoDB or Cassandra, and easily place our reactive microservices inside one system together with synchronous REST microservices.