While developing a new application we should never forget about testing. This term seems to be particularly important when working with microservices. Microservices testing requires different approach than tests designing for monolithic applications. As far as monolithic testing is concerned, the main focus is put on unit testing and also in most cases integration tests with the database layer. In the case of microservices, the most important test seems to be interactions between those microservices. Although every microservice is independently developed and released the change in one of them can affect on all which are interacting with that service. Interaction between them is realized by messages. Usually these are messages send via REST or AMQP protocols.
We can divide five different layers of microservices tests. The first three of them are same as for monolith applications.
Unit tests – we are testing the smallest pieces of code, for example single method or component and mocking every call of other methods or components. There are many popular frameworks that supporting unit tests in java like JUnit, TestNG and Mockito for mocking. The main task of this type of testing is to confirm that the implementation meets the requirements.
Integration tests – we are testing interaction and communication between components basing on their interfaces with external services mocked out.
End-to-end test – also known as functional tests. The main goal of that tests is to verify if the system meets the external requirements. It means that we should design test scenarios which test all the microservices take a part in that process.
Contract tests – test at the boundary of an external service verifying that it meets the contract expected by a consuming service
Component tests – limits the scope of the exercised software to a portion of the system under test, manipulating the system through internal code interfaces and using test doubles to isolate the code under test from other components.
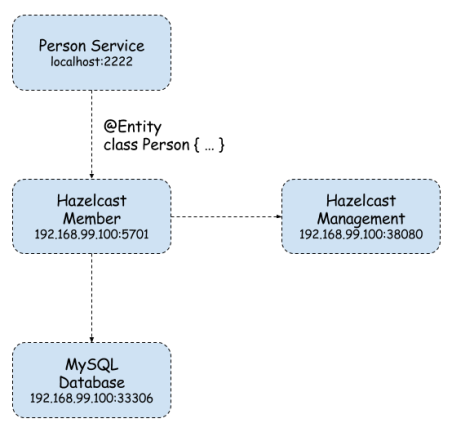
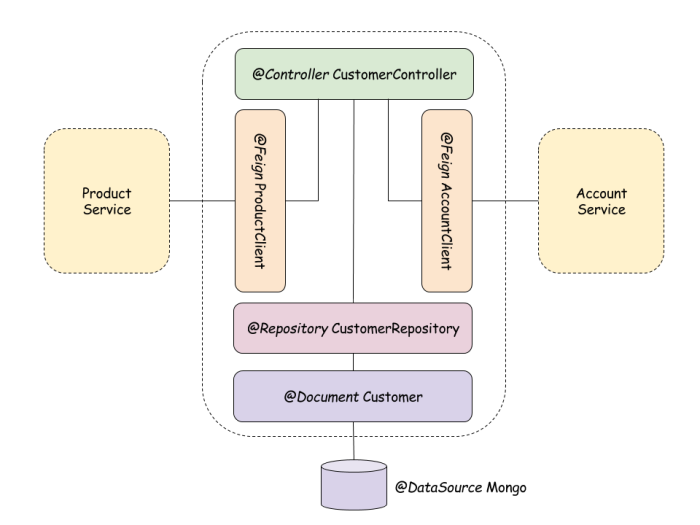
In the figure below we can see the component diagram of the one sample microservice (customer service). That architecture is similar for all other sample microservices described in that post. Customer service is interacting with Mongo database and storing there all customers. Mapped between object and database is realized by Spring Data @Document. We also use @Repository component as a DAO for Customer entity. Communication with other microservices is realized by @Feign REST client. Customer service collects all customer’s accounts and products from external microservices. @Repository and @Feign clients are injected into the @Controller which is exposed outside via REST resource.
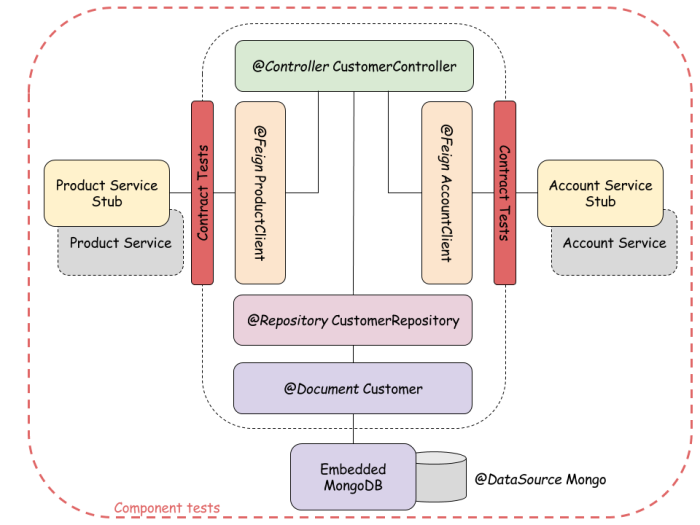
In this article I’ll show you contract and component tests for sample microservices architecture. In the figure below you can see test strategy for architecture showed in previous picture. For our tests we use embedded in-memory Mongo database and RESTful stubs generated with Spring Cloud Contract framework.
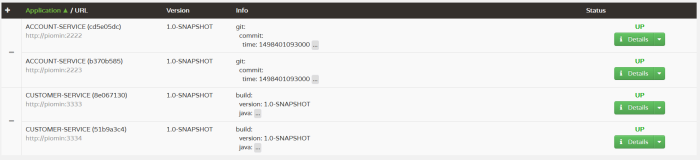
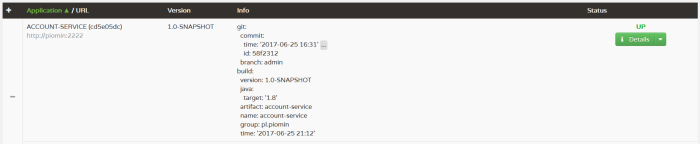
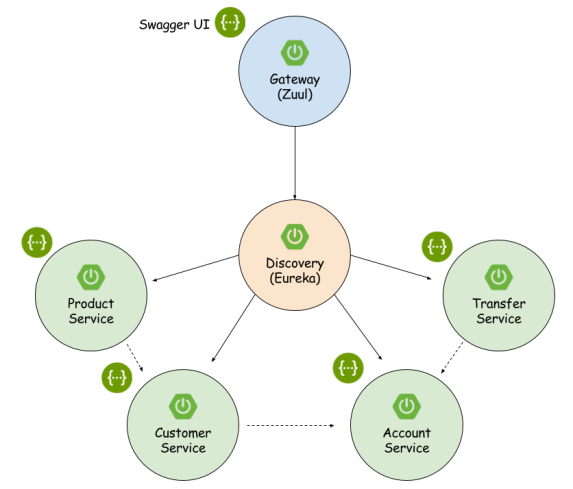
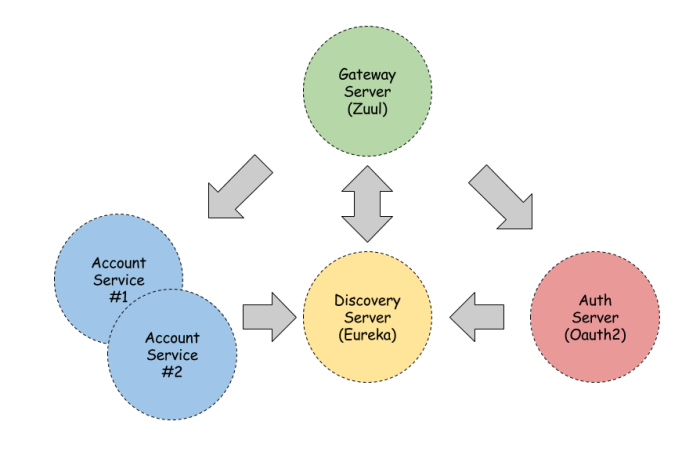
Now, let’s take a look on the big picture. We have four microservices interacting with each other like we see in the figure below. Spring Cloud Contract uses WireMock in the backgroud for recording and matching requests and responses. For testing purposes Eureka discovering on all microservices needs to be disabled.

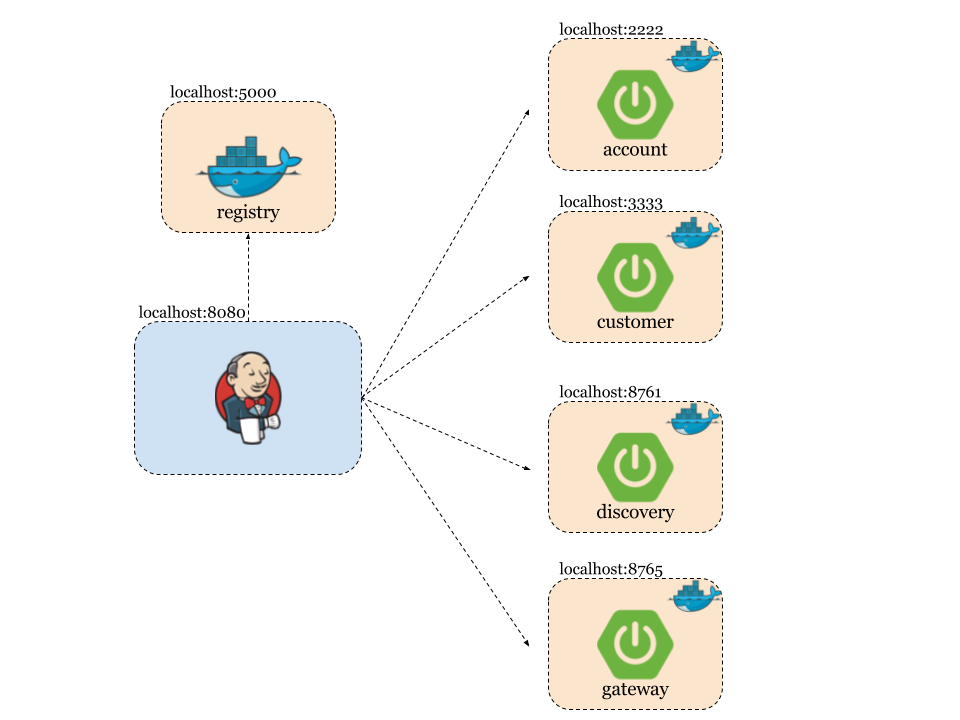
Sample application source code is available on GitHub. All microservices are basing on Spring Boot and Spring Cloud (Eureka, Zuul, Feign, Ribbon) frameworks. Interaction with Mongo database is realized with Spring Data MongoDB (spring-boot-starter-data-mongodb dependency in pom.xml) library. DAO is really simple. It extends MongoRepository CRUD component. @Repository and @Feign clients are injected into CustomerController.
public interface CustomerRepository extends MongoRepository<Customer, String> {
public Customer findByPesel(String pesel);
public Customer findById(String id);
}
Here’s full controller code.
@RestController
public class CustomerController {
@Autowired
private AccountClient accountClient;
@Autowired
private ProductClient productClient;
@Autowired
CustomerRepository repository;
protected Logger logger = Logger.getLogger(CustomerController.class.getName());
@RequestMapping(value = "/customers/pesel/{pesel}", method = RequestMethod.GET)
public Customer findByPesel(@PathVariable("pesel") String pesel) {
logger.info(String.format("Customer.findByPesel(%s)", pesel));
return repository.findByPesel(pesel);
}
@RequestMapping(value = "/customers", method = RequestMethod.GET)
public List<Customer> findAll() {
logger.info("Customer.findAll()");
return repository.findAll();
}
@RequestMapping(value = "/customers/{id}", method = RequestMethod.GET)
public Customer findById(@PathVariable("id") String id) {
logger.info(String.format("Customer.findById(%s)", id));
Customer customer = repository.findById(id);
List<Account> accounts = accountClient.getAccounts(id);
logger.info(String.format("Customer.findById(): %s", accounts));
customer.setAccounts(accounts);
return customer;
}
@RequestMapping(value = "/customers/withProducts/{id}", method = RequestMethod.GET)
public Customer findWithProductsById(@PathVariable("id") String id) {
logger.info(String.format("Customer.findWithProductsById(%s)", id));
Customer customer = repository.findById(id);
List<Product> products = productClient.getProducts(id);
logger.info(String.format("Customer.findWithProductsById(): %s", products));
customer.setProducts(products);
return customer;
}
@RequestMapping(value = "/customers", method = RequestMethod.POST)
public Customer add(@RequestBody Customer customer) {
logger.info(String.format("Customer.add(%s)", customer));
return repository.save(customer);
}
@RequestMapping(value = "/customers", method = RequestMethod.PUT)
public Customer update(@RequestBody Customer customer) {
logger.info(String.format("Customer.update(%s)", customer));
return repository.save(customer);
}
}
To replace external Mongo database with embedded in-memory instance during automated tests we only have to add following dependency to pom.xml.
<dependency>
<groupId>de.flapdoodle.embed</groupId>
<artifactId>de.flapdoodle.embed.mongo</artifactId>
<scope>test</scope>
</dependency>
If we using different addresses and connection credentials also application seetings should be overriden in src/test/resources. Here’s application.yml file for testing. In the bottom there is a configuration for disabling Eureka discovering.
server:
port: ${PORT:3333}
spring:
application:
name: customer-service
data:
mongodb:
host: localhost
port: 27017
logging:
level:
org.springframework.cloud.contract: TRACE
eureka:
client:
enabled: false
In-memory MongoDB instance is started automatically during Spring Boot JUnit test. The next step is to add Spring Cloud Contract dependencies.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-contract-stub-runner</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-contract-verifier</artifactId>
<scope>test</scope>
</dependency>
To enable automated tests generation by Spring Cloud Contract we also have to add following plugin into pom.xml.
<plugin>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-contract-maven-plugin</artifactId>
<version>1.1.0.RELEASE</version>
<extensions>true</extensions>
<configuration>
<packageWithBaseClasses>pl.piomin.microservices.advanced.customer.api</packageWithBaseClasses>
</configuration>
</plugin>
Property packageWithBaseClasses defines package where base classes extended by generated test classes are stored. Here’s base test class for account service tests. In our sample architecture account service is only a produces it does not consume any services.
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {Application.class})
public class ApiScenario1Base {
@Autowired
private WebApplicationContext context;
@Before
public void setup() {
RestAssuredMockMvc.webAppContextSetup(context);
}
}
As opposed to the account service customer service consumes some services for collecting customer’s account and products. That’s why base test class for customer service needs to define stub artifacts data.
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {Application.class})
@AutoConfigureStubRunner(ids = {"pl.piomin:account-service:+:stubs:2222"}, workOffline = true)
public class ApiScenario1Base {
@Autowired
private WebApplicationContext context;
@Before
public void setup() {
RestAssuredMockMvc.webAppContextSetup(context);
}
}
Test classes are generated on the basis of contracts defined in src/main/resources/contracts. Such contracts can be implemented using Groovy language. Here’s sample contract for adding new account.
org.springframework.cloud.contract.spec.Contract.make {
request {
method 'POST'
url '/accounts'
body([
id: "1234567890",
number: "12345678909",
balance: 1234,
customerId: "123456789"
])
headers {
contentType('application/json')
}
}
response {
status 200
body([
id: "1234567890",
number: "12345678909",
balance: 1234,
customerId: "123456789"
])
headers {
contentType('application/json')
}
}
}
Test class are generated under target/generated-test-sources catalog. Here’s generated class for the code above.
@FixMethodOrder(MethodSorters.NAME_ASCENDING)
public class Scenario1Test extends ApiScenario1Base {
@Test
public void validate_1_postAccount() throws Exception {
// given:
MockMvcRequestSpecification request = given()
.header("Content-Type", "application/json")
.body("{\"id\":\"1234567890\",\"number\":\"12345678909\",\"balance\":1234,\"customerId\":\"123456789\"}");
// when:
ResponseOptions response = given().spec(request)
.post("/accounts");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).matches("application/json.*");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("id").isEqualTo("1234567890");
assertThatJson(parsedJson).field("number").isEqualTo("12345678909");
assertThatJson(parsedJson).field("balance").isEqualTo(1234);
assertThatJson(parsedJson).field("customerId").isEqualTo("123456789");
}
@Test
public void validate_2_postAccount() throws Exception {
// given:
MockMvcRequestSpecification request = given()
.header("Content-Type", "application/json")
.body("{\"id\":\"1234567891\",\"number\":\"12345678910\",\"balance\":4675,\"customerId\":\"123456780\"}");
// when:
ResponseOptions response = given().spec(request)
.post("/accounts");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).matches("application/json.*");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("id").isEqualTo("1234567891");
assertThatJson(parsedJson).field("customerId").isEqualTo("123456780");
assertThatJson(parsedJson).field("number").isEqualTo("12345678910");
assertThatJson(parsedJson).field("balance").isEqualTo(4675);
}
@Test
public void validate_3_getAccounts() throws Exception {
// given:
MockMvcRequestSpecification request = given();
// when:
ResponseOptions response = given().spec(request)
.get("/accounts");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).matches("application/json.*");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).array().contains("balance").isEqualTo(1234);
assertThatJson(parsedJson).array().contains("customerId").isEqualTo("123456789");
assertThatJson(parsedJson).array().contains("id").matches("[0-9]{10}");
assertThatJson(parsedJson).array().contains("number").isEqualTo("12345678909");
}
}
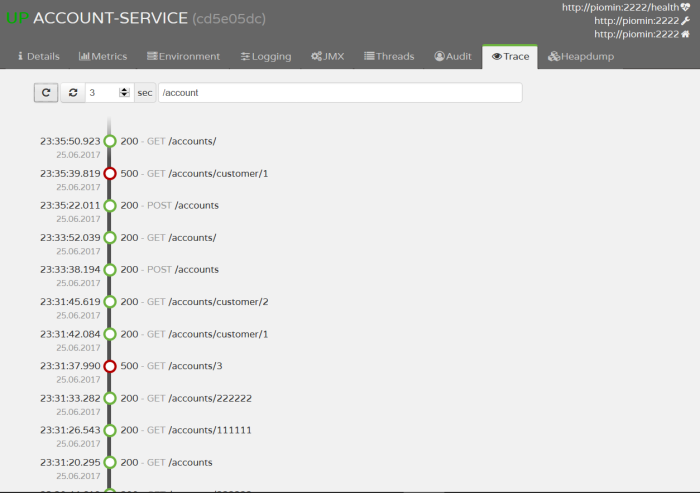
In the generated class there are three JUnit tests because I used scenario mechanisms available in Spring Cloud Contract. There are three groovy files inside scenario1 catalog like we can see in the picture below. The number in every file’s prefix defines tests order. Second scenario has only one definition file and is also used in the customer service (findById API method). Third scenario has four definition files and is used in the transfer service (execute API method).

Like I mentioned before interaction between microservices is realized by @FeignClient. WireMock used by Spring Cloud Contract records request/response defined in scenario2 inside account service. Then recorded interaction is used by @FeignClient during tests instead of calling real service which is not available.
@FeignClient("account-service")
public interface AccountClient {
@RequestMapping(method = RequestMethod.GET, value = "/accounts/customer/{customerId}", consumes = {MediaType.APPLICATION_JSON_VALUE})
List<Account> getAccounts(@PathVariable("customerId") String customerId);
}
All the tests are generated and run during Maven build, for example mvn clean install command. If you are interested in more details and features of Spring Cloud Contract you can it here.
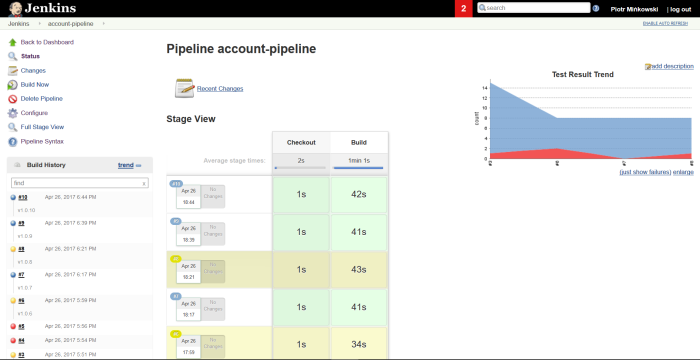
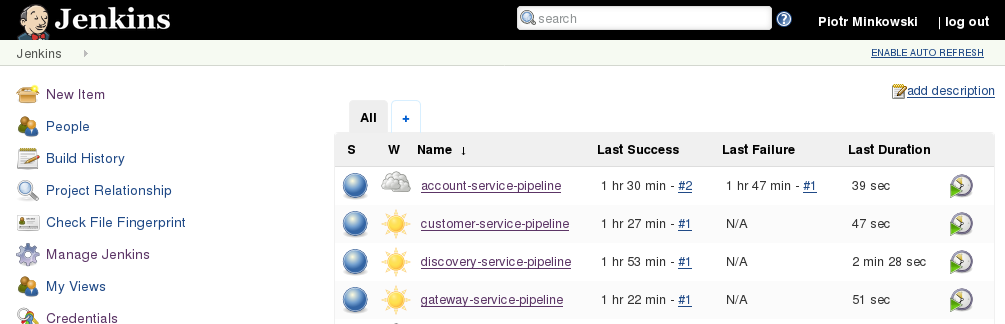
Finally, we can define Continuous Integration pipeline for our microservices. Each of them should be build independently. More about Continuous Integration / Continuous Delivery environment could be read in one of previous post How to setup Continuous Delivery environment. Here’s sample pipeline created with Jenkins Pipeline Plugin for account service. In Checkout stage we are updating our source code working for the newest version from repository. In the Build stage we are starting from checking out project version set inside pom.xml, then we build application using mvn clean install command. Finally, we are recording unit tests result using junit pipeline method. Same pipelines can be configured for all other microservices. In described sample all microservices are placed in the same Git repository with one Maven version for simplicity. But we can imagine that every microservice could be inside different repository with independent version in pom.xml. Tests will always be run with the newest version of stubs, which is set in that fragment of base test class with +: @AutoConfigureStubRunner(ids = {“pl.piomin:account-service:+:stubs:2222”}, workOffline = true)
node {
withMaven(maven: 'Maven') {
stage ('Checkout') {
git url: 'https://github.com/piomin/sample-spring-microservices-advanced.git', credentialsId: 'github-piomin', branch: 'testing'
}
stage ('Build') {
def pom = readMavenPom file: 'pom.xml'
def version = pom.version.replace("-SNAPSHOT", ".${currentBuild.number}")
env.pom_version = version
print 'Build version: ' + version
currentBuild.description = "v${version}"
dir('account-service') {
bat "mvn clean install -Dmaven.test.failure.ignore=true"
}
junit '**/target/surefire-reports/TEST-*.xml'
}
}
}
Here’s pipeline vizualization on Jenkins Management Dashboard.