In this guide I’m going to discuss some more advanced topics related to GraphQL and databases, like filtering or relationship fetching. Of course, before proceeding to the more advanced issues I will take a moment to describe the basics – something you can found in many other articles. If you already had the opportunity to familiarize yourself with the concept over GraphQL you may have some questions. Probably one of them is: “Ok. It’s nice. But what if I would like to use GraphQL in the real application that connects to database and provides API for more advanced queries?”. If that is your main question, my current article is definitely for you. If you are thinking about using GraphQL in your microservices architecture you may also refer to my previous article GraphQL – The Future of Microservices?. Continue reading “An Advanced Guide to GraphQL with Spring Boot”
Tag: JPA
Distributed Transactions in Microservices with Spring Boot
When I’m talking about microservices with other people they are often asking me about approach to distributed transactions. My advice is always the same – try to completely avoid distributed transactions in your microservices architecture. It is a very complex process with a lot of moving parts that can fail. That’s why it does not fit to the nature of microservices-based systems.
Continue reading “Distributed Transactions in Microservices with Spring Boot”

JPA Data Access with Micronaut Data
When I have writing some articles comparing Spring and Micronaut frameworks recently, I have taken a note of many comments about lack of built-in ORM and data repositories support in Micronaut. Spring provides this feature for a long time through Spring Data project. The good news is that the Micronaut team is close to complete work on first version of their project with ORM support. The project called Micronaut Predator (short for Precomputed Data Repositories) is still under active development, and currently we may access just the snapshot version. However, the authors are introducing it is as more efficient with reduced memory consumption than competitive solutions like Spring Data or Grails GORM. In short, this could be achieved thanks to Ahead of Time (AoT) compilation to pre-compute queries for repository interfaces that are then executed by a thin, lightweight runtime layer, and avoiding usage of reflection or runtime proxies. Continue reading “JPA Data Access with Micronaut Data”

Kotlin Microservices with Micronaut, Spring Cloud and JPA
Micronaut Framework provides support for Kotlin built upon Kapt compiler plugin. It also implements the most popular cloud-native patterns like distributed configuration, service discovery and client-side load balancing. These features allows to include your application built on top of Micronaut into the existing microservices-based system. The most popular example of such approach may be an integration with Spring Cloud ecosystem. If you have already used Spring Cloud, it is very likely you built your microservices-based architecture using Eureka discovery server and Spring Cloud Config as a configuration server. Beginning from version 1.1 Micronaut supports both these popular tools being a part of Spring Cloud project. That’s a good news, because in version 1.0 the only supported distributed solution was Consul, and there were no possibility to use Eureka discovery together with Consul property source (running them together ends with exception). Continue reading “Kotlin Microservices with Micronaut, Spring Cloud and JPA”

Up-to-date cache with EclipseLink and Oracle
One of the most useful feature provided by ORM libraries is a second-level cache, usually called L2. L2 object cache reduces database access for entities and their relationships. It is enabled by default in the most popular JPA implementations like Hibernate or EclipseLink. That won’t be a problem, unless a table inside a database is not modified directly by third-party applications, or by the other instance of the same application in a clustered environment. One of the available solutions to this problem is in-memory data grid, which stores all data in a memory, and is distributed across many nodes inside a cluster. Such a tools like Hazelcast or Apache Ignite has been described several times in my blog. If you are interested in one of that tools I recommend you read one of my previous article bout it: Hazelcast Hot Cache with Striim.
However, we won’t discuss about it in this article. Today, I would like to talk about Continuous Query Notification feature provided by Oracle Database. It solves a problem with updating or invalidating a cache when the data changes in the database. Oracle JDBC drivers provide support for it since 11g Release 1. This functionality is based on receiving invalidation events from the JDBC drivers. Fortunately, EclipseLink extends that feature in their solution called EclipseLink Database Change Notification. In this article I’m going to show you how to implement it using Spring Data JPA together with EclipseLink library.
How it works
The most useful functionality provided by the Oracle Database Continuous Query Notification is an ability to raise database events when rows in a table were modified. It enables client applications to register queries with the database and receive notifications in response to DML or DDL changes on the objects associated with the queries. To detect modifications, EclipseLink DCN uses Oracle ROWID to intercept changes in the table. ROWID is included to all queries for a DCN-enabled class. EclipseLink also retrieves ROWID of saved entity after an insert operation, and maintains a cache index on that ROWID. It also selects the database transaction ID once for each transaction to avoid invalidating the cache during the processing of transaction.
When a database sends a notification it usually contains the followoing information:
- Names of the modifying objects, for example a name of changed table
- Type of change. The possible values are INSERT, UPDATE, DELETE, ALTER TABLE, or DROP TABLE
- Oracle’s ROWID of changed record
Running Oracle database locally
Before starting working on our sample application we need to have Oracle database installed. Fortunately, there are some Docker images with Oracle Standard Edition 12c. The command visible below starts Oracle XE version and exposes it on default 1521 port. It is also possible to use web console available under port 9080.
$ docker run -d --name oracle -p 9080:8080 -p 1521:1521 sath89/oracle-12c
We need to have sysdba role in order to be able to grant privilege CHANGE NOTIFICATION to our database. The default password for user system is oracle.
GRANT CHANGE NOTIFICATION TO PIOMIN;
You may use any Oracle client like Oracle SQL Developer to connect with database or just login to a web console. Since I run Docker on Windows it is available on my laptop under address http://192.168.99.100:9080/em. Of course it is Oracle, so you need to settle in for a long haul, and wait until it starts. You can observer a progress of an installation by running command docker logs -f oracle. When you finally see a “100% complete” log entry you may grant the required privileges to the existing user or create a new one with a set of needed privileges, and proceed to the next step.
Sample application
The sample application source code is available on GitHub under address https://github.com/piomin/sample-eclipselink-jpa.git. It is Spring Boot application that uses Spring Data JPA as a data access layer implementation. Because the default JPA provider used in that project is EclipseLink, we should remember about excluding Hibernate libraries from starters spring-boot-starter-data-jpa and spring-boot-starter-web. Besides a standard EclipseLink library for JPA, we also have to include EclipseLink implementation for Oracle database (org.eclipse.persistence.oracle) and Oracle JDBC driver.
<dependency> <groupId>org.eclipse.persistence</groupId> <artifactId>org.eclipse.persistence.jpa</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.eclipse.persistence</groupId> <artifactId>org.eclipse.persistence.oracle</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc7</artifactId> <version>12.1.0.1</version> </dependency>
The next step is to provide connection settings to Oracle database launched as a Docker container. Do not try to do it through application.yml properties, because Spring Boot by default uses HikariCP for connection pooling. This in turn causes a conflict with Oracle datasource during application bootstrap. The following datasource declaration would work succesfully.
@Bean
public DataSource dataSource() {
final DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("oracle.jdbc.driver.OracleDriver");
dataSource.setUrl("jdbc:oracle:thin:@192.168.99.100:1521:xe");
dataSource.setUsername("piomin");
dataSource.setPassword("Piot_123");
return dataSource;
}
EclipseLink with Database Change Notification
EclipseLink needs some specific configuration settings to succesfully work with Spring Boot and Spring Data JPA. These settings may be provided inside @Configuration class that extends JpaBaseConfiguration class. First, we should set EclipseLinkJpaVendorAdapter as default JPA vendor adapter. Then, we may configure some additional JPA settings like detailed logging level or automatic creation of database objects during application startup. However, the most important thing for us in the fragment of source code visible below is Oracle Continuous Query Notification settings.
EclipseLink CQN support is enabled by the OracleChangeNotificationListener listener which integrates with Oracle JDBC in order to received database change notifications. The full class name of the listener should be passed as a value of eclipselink.cache.database-event-listener property. EclipseLink by default enabled L2 cache for all entities, and respectively all tables in the persistence unit are registered for a change notification. You may exclude some of them by using the databaseChangeNotificationType attribute of the @Cache annotation on the selected entity.
@Configuration
@EnableAutoConfiguration
public class JpaConfiguration extends JpaBaseConfiguration {
protected JpaConfiguration(DataSource dataSource, JpaProperties properties, ObjectProvider jtaTransactionManager, ObjectProvider transactionManagerCustomizers) {
super(dataSource, properties, jtaTransactionManager, transactionManagerCustomizers);
}
@Override
protected AbstractJpaVendorAdapter createJpaVendorAdapter() {
return new EclipseLinkJpaVendorAdapter();
}
@Override
protected Map getVendorProperties() {
HashMap map = new HashMap();
map.put(PersistenceUnitProperties.WEAVING, InstrumentationLoadTimeWeaver.isInstrumentationAvailable() ? "true" : "static");
map.put(PersistenceUnitProperties.DDL_GENERATION, "create-or-extend-tables");
map.put(PersistenceUnitProperties.LOGGING_LEVEL, SessionLog.FINEST_LABEL);
map.put(PersistenceUnitProperties.DATABASE_EVENT_LISTENER, "org.eclipse.persistence.platform.database.oracle.dcn.OracleChangeNotificationListener");
return map;
}
}
What is worth mentioning EclipseLink’s CQN integration has some important limitations:
- Changes to an object’s secondary tables will not trigger it to be invalidate unless a version is used and updated in the primary table
- Changes to an object’s
OneToMany,ManyToMany, andElementCollectionrelationships will not trigger it to be invalidate unless a version is used and updated in the primary table
The conclusion from these limitations is obvious. We should enable optimistic locking by including an @Version in our entities. The column with @Version in the primary table will always be updated, and the object will always be invalidated. There are three entities implemented. Entity Order is in many-to-one relationship with Product and Customer entities. All these classes has @Version feature enabled.
@Entity
@Table(name = "JPA_ORDER")
public class Order {
@Id
@SequenceGenerator(sequenceName = "SEQ_ORDER", allocationSize = 1, initialValue = 1, name = "orderSequence")
@GeneratedValue(generator = "orderSequence", strategy = GenerationType.SEQUENCE)
private Long id;
@ManyToOne
private Customer customer;
@ManyToOne
private Product product;
@Enumerated
private OrderStatus status;
private int count;
@Version
private long version;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Customer getCustomer() {
return customer;
}
public void setCustomer(Customer customer) {
this.customer = customer;
}
public Product getProduct() {
return product;
}
public void setProduct(Product product) {
this.product = product;
}
public OrderStatus getStatus() {
return status;
}
public void setStatus(OrderStatus status) {
this.status = status;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public long getVersion() {
return version;
}
public void setVersion(long version) {
this.version = version;
}
@Override
public String toString() {
return "Order [id=" + id + ", product=" + product + ", status=" + status + ", count=" + count + "]";
}
}
Testing
After launching your application you see the following logs generated with Finest level.
[EL Finest]: connection: 2018-03-23 15:45:50.591--ServerSession(465621833)--Thread(Thread[main,5,main])--Registering table [JPA_PRODUCT] for database change event notification. [EL Finest]: connection: 2018-03-23 15:45:50.608--ServerSession(465621833)--Thread(Thread[main,5,main])--Registering table [JPA_CUSTOMER] for database change event notification. [EL Finest]: connection: 2018-03-23 15:45:50.616--ServerSession(465621833)--Thread(Thread[main,5,main])--Registering table [JPA_ORDER] for database change event notification.
The registration are stored in table user_change_notification_regs, which is available for your application’s user (PIOMIN).
$ SELECT regid, table_name FROM user_change_notification_regs;
REGID TABLE_NAME
---------- ---------------------------------------------------------------
326 PIOMIN.JPA_PRODUCT
326 PIOMIN.JPA_CUSTOMER
326 PIOMIN.JPA_ORDER
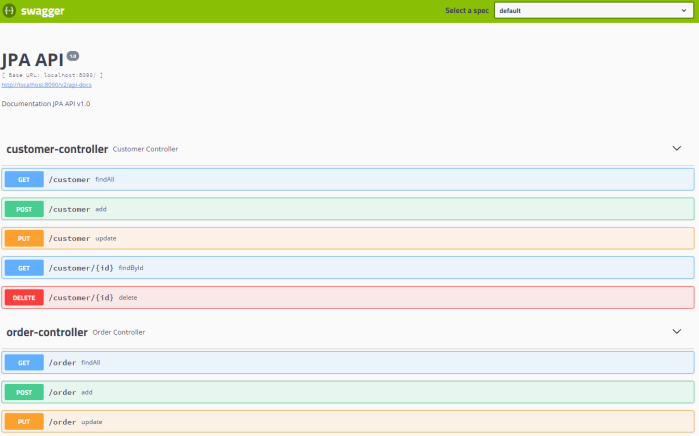
Our sample application exposes Swagger documentation of API, which may be accessed under address http://localhost:8090/swagger-ui.html. You can create or find some entities using it. If try to find the same entity several times you would see that the only first invoke generates SQL query in logs, while all others are taken from a cache. Now, try to change that record using any Oracle’s client like Oracle SQL Developer, and verify if cache has been succesfully refreshed.
Summary
When I first heard about Oracle Database Change Notification supported by EclipseLink JPA vendor, my expectations were really high. It is very interesting solution, which guarantees automatic cache refresh after changes performed on database tables by third-party application avoiding your cache. However, I had some problems with that solution during tests. In some cases it just doesn’t work, and the detection of errors was really troublesome. It would be fine if such a solution could be also available for other databases than Oracle and JPA vendors like Hibernate.

JPA caching with Hazelcast, Hibernate and Spring Boot
Preface
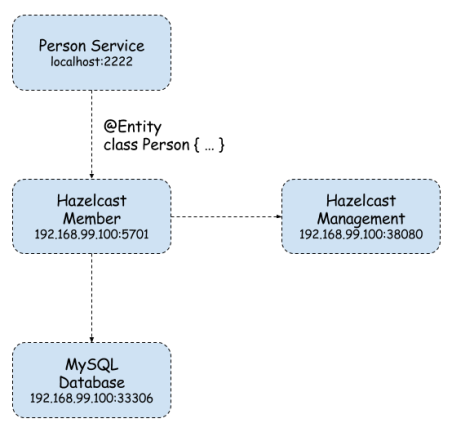
In-Memory Data Grid is an in-memory distributed key-value store that enables caching data using distributed clusters. Do not confuse this solution with in-memory or nosql database. In most cases it is used for performance reasons – all data is stored in RAM not in the disk like in traditional databases. For the first time I had a touch with in-memory data grid while we considering moving to Oracle Coherence in one of organizations I had been working before. The solution really made me curious. Oracle Coherence is obviously a paid solution, but there are also some open source solutions among which the most interesting seem to be Apache Ignite and Hazelcast. Today I’m going to show you how to use Hazelcast for caching data stored in MySQL database accessed by Spring Data DAO objects. Here’s the figure illustrating architecture of presented solution.
Implementation
-
Starting Docker containers
We use three Docker containers. First with MySQL database, second with Hazelcast instance and third for Hazelcast Management Center – UI dashboard for monitoring Hazelcast cluster instances.
docker run -d --name mysql -p 33306:3306 mysql docker run -d --name hazelcast -p 5701:5701 hazelcast/hazelcast docker run -d --name hazelcast-mgmt -p 38080:8080 hazelcast/management-center:latest
If we would like to connect with Hazelcast Management Center from Hazelcast instance we need to place custom hazelcast.xml in /opt/hazelcast catalog inside Docker container. This can be done in two ways, by extending hazelcast base image or just by copying file to existing hazelcast container and restarting it.
docker run -d --name hazelcast -p 5701:5701 hazelcast/hazelcast docker stop hazelcast docker start hazelcast
Here’s the most important Hazelcast’s configuration file fragment.
<hazelcast xmlns="http://www.hazelcast.com/schema/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.hazelcast.com/schema/config http://www.hazelcast.com/schema/config/hazelcast-config-3.8.xsd">
<group>
<name>dev</name>
<password>dev-pass</password>
</group>
<management-center enabled="true" update-interval="3">http://192.168.99.100:38080/mancenter</management-center>
...
</hazelcast>
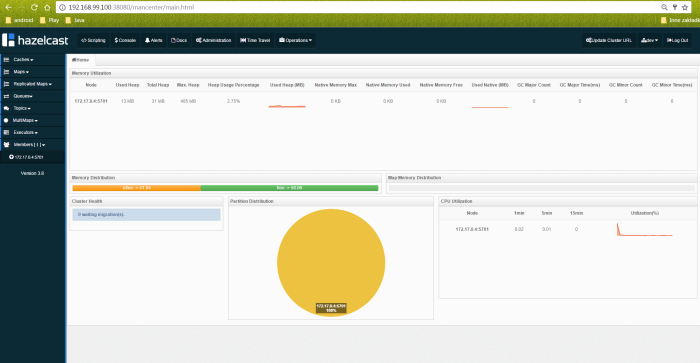
Hazelcast Dashboard is available under http://192.168.99.100:38080/mancenter address. We can monitor there all running cluster members, maps and some other parameters.
-
Maven configuration
Project is based on Spring Boot 1.5.3.RELEASE. We also need to add Spring Web and MySQL Java connector dependencies. Here’s root project pom.xml.
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.3.RELEASE</version> </parent> ... <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> ... </dependencies>
Inside person-service module we declared some other dependencies to Hazelcast artifacts and Spring Data JPA. I had to override managed hibernate-core version for Spring Boot 1.5.3.RELEASE, because Hazelcast didn’t worked properly with 5.0.12.Final. Hazelcast needs hibernate-core in 5.0.9.Final version. Otherwise, an exception occurs when starting application.
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>com.hazelcast</groupId> <artifactId>hazelcast</artifactId> </dependency> <dependency> <groupId>com.hazelcast</groupId> <artifactId>hazelcast-client</artifactId> </dependency> <dependency> <groupId>com.hazelcast</groupId> <artifactId>hazelcast-hibernate5</artifactId> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>5.0.9.Final</version> </dependency> </dependencies>
-
Hibernate Cache configuration
Probably you can configure it in several different ways, but for me the most suitable solution was inside application.yml. Here’s YAML configurarion file fragment. I enabled L2 Hibernate cache, set Hazelcast native client address, credentials and cache factory class HazelcastCacheRegionFactory. We can also set HazelcastLocalCacheRegionFactory. The differences between them are in performance – local factory is faster since its operations are handled as distributed calls. While if you use HazelcastCacheRegionFactory, you can see your maps on Management Center.
spring:
application:
name: person-service
datasource:
url: jdbc:mysql://192.168.99.100:33306/datagrid?useSSL=false
username: datagrid
password: datagrid
jpa:
properties:
hibernate:
show_sql: true
cache:
use_query_cache: true
use_second_level_cache: true
hazelcast:
use_native_client: true
native_client_address: 192.168.99.100:5701
native_client_group: dev
native_client_password: dev-pass
region:
factory_class: com.hazelcast.hibernate.HazelcastCacheRegionFactory
-
Application code
First, we need to enable caching for Person @Entity.
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
@Entity
public class Person implements Serializable {
private static final long serialVersionUID = 3214253910554454648L;
@Id
@GeneratedValue
private Integer id;
private String firstName;
private String lastName;
private String pesel;
private int age;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getPesel() {
return pesel;
}
public void setPesel(String pesel) {
this.pesel = pesel;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [id=" + id + ", firstName=" + firstName + ", lastName=" + lastName + ", pesel=" + pesel + "]";
}
}
DAO is implemented using Spring Data CrudRepository. Sample application source code is available on GitHub.
public interface PersonRepository extends CrudRepository<Person, Integer> {
public List<Person> findByPesel(String pesel);
}
Testing
Let’s insert a little more data to the table. You can use my AddPersonRepositoryTest for that. It will insert 1M rows into the person table. Finally, we can call enpoint http://localhost:2222/persons/{id} twice with the same id. For me, it looks like below: 22ms for first call, 3ms for next call which is read from L2 cache. Entity can be cached only by primary key. If you call http://localhost:2222/persons/pesel/{pesel} entity will always be searched bypassing the L2 cache.
2017-05-05 17:07:27.360 DEBUG 9164 --- [nio-2222-exec-9] org.hibernate.SQL : select person0_.id as id1_0_0_, person0_.age as age2_0_0_, person0_.first_name as first_na3_0_0_, person0_.last_name as last_nam4_0_0_, person0_.pesel as pesel5_0_0_ from person person0_ where person0_.id=? Hibernate: select person0_.id as id1_0_0_, person0_.age as age2_0_0_, person0_.first_name as first_na3_0_0_, person0_.last_name as last_nam4_0_0_, person0_.pesel as pesel5_0_0_ from person person0_ where person0_.id=? 2017-05-05 17:07:27.362 DEBUG 9164 --- [nio-2222-exec-9] o.h.l.p.e.p.i.ResultSetProcessorImpl : Starting ResultSet row #0 2017-05-05 17:07:27.362 DEBUG 9164 --- [nio-2222-exec-9] l.p.e.p.i.EntityReferenceInitializerImpl : On call to EntityIdentifierReaderImpl#resolve, EntityKey was already known; should only happen on root returns with an optional identifier specified 2017-05-05 17:07:27.363 DEBUG 9164 --- [nio-2222-exec-9] o.h.engine.internal.TwoPhaseLoad : Resolving associations for [pl.piomin.services.datagrid.person.model.Person#444] 2017-05-05 17:07:27.364 DEBUG 9164 --- [nio-2222-exec-9] o.h.engine.internal.TwoPhaseLoad : Adding entity to second-level cache: [pl.piomin.services.datagrid.person.model.Person#444] 2017-05-05 17:07:27.373 DEBUG 9164 --- [nio-2222-exec-9] o.h.engine.internal.TwoPhaseLoad : Done materializing entity [pl.piomin.services.datagrid.person.model.Person#444] 2017-05-05 17:07:27.373 DEBUG 9164 --- [nio-2222-exec-9] o.h.r.j.i.ResourceRegistryStandardImpl : HHH000387: ResultSet's statement was not registered 2017-05-05 17:07:27.374 DEBUG 9164 --- [nio-2222-exec-9] .l.e.p.AbstractLoadPlanBasedEntityLoader : Done entity load : pl.piomin.services.datagrid.person.model.Person#444 2017-05-05 17:07:27.374 DEBUG 9164 --- [nio-2222-exec-9] o.h.e.t.internal.TransactionImpl : committing 2017-05-05 17:07:30.168 DEBUG 9164 --- [nio-2222-exec-6] o.h.e.t.internal.TransactionImpl : begin 2017-05-05 17:07:30.171 DEBUG 9164 --- [nio-2222-exec-6] o.h.e.t.internal.TransactionImpl : committing
Query Cache
We can enable JPA query caching by marking repository method with @Cacheable annotation and adding @EnableCaching to main class definition.
public interface PersonRepository extends CrudRepository<Person, Integer> {
@Cacheable("findByPesel")
public List<Person> findByPesel(String pesel);
}
In addition to the @EnableCaching annotation we should declare HazelcastIntance and CacheManager beans. As a cache manager HazelcastCacheManager from hazelcast-spring library is used.
@SpringBootApplication
@EnableCaching
public class PersonApplication {
public static void main(String[] args) {
SpringApplication.run(PersonApplication.class, args);
}
@Bean
HazelcastInstance hazelcastInstance() {
ClientConfig config = new ClientConfig();
config.getGroupConfig().setName("dev").setPassword("dev-pass");
config.getNetworkConfig().addAddress("192.168.99.100");
config.setInstanceName("cache-1");
HazelcastInstance instance = HazelcastClient.newHazelcastClient(config);
return instance;
}
@Bean
CacheManager cacheManager() {
return new HazelcastCacheManager(hazelcastInstance());
}
}
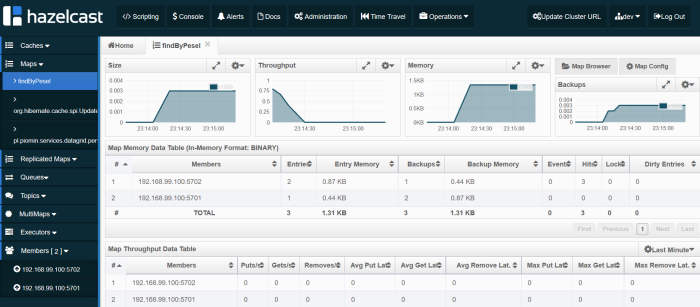
Now, we should try find person by PESEL number by calling endpoint http://localhost:2222/persons/pesel/{pesel}. Cached query is stored as a map as you see in the picture below.
Clustering
Before final words let me say a little about clustering, what is the key functionality of Hazelcast in memory data grid. In the previous chapters we based on single Hazelcast instance. Let’s begin from running second container with Hazelcast exposed on different port.
docker run -d --name hazelcast2 -p 5702:5701 hazelcast/hazelcast
Now we should perform one change in hazelcast.xml configuration file. Because data grid is ran inside docker container the public address has to be set. For the first container it is 192.168.99.100:5701, and for second 192.168.99.100:5702, because it is exposed on 5702 port.
<network>
...
<public-address>192.168.99.100:5701</public-address>
...
</network>
When starting person-service application you should see in the logs similar to visible below – connection with two cluster members.
Members [2] {
Member [192.168.99.100]:5702 - 04f790bc-6c2d-4c21-ba8f-7761a4a7422c
Member [192.168.99.100]:5701 - 2ca6e30d-a8a7-46f7-b1fa-37921aaa0e6b
}
All Hazelcast running instances are visible in Management Center.
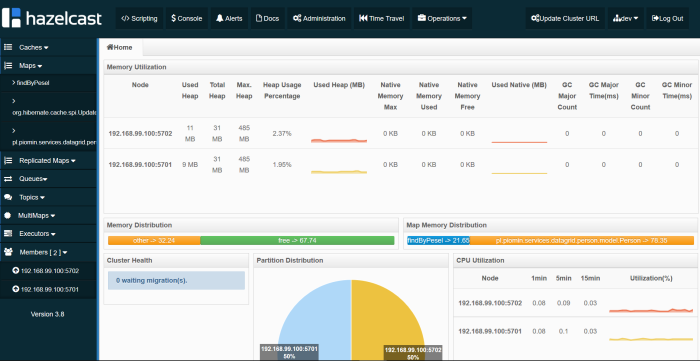
Conclusion
Caching and clustering with Hazelcast are simple and fast. We can cache JPA entities and queries. Monitoring is realized via Hazelcast Management Center dashboard. One problem for me is that I’m able to cache entities only by primary key. If I would like to find entity by other index like PESEL number I had to cache findByPesel query. Even if entity was cached before by id query will not find it in the cache but perform SQL on database. Only next query call is cached. I’ll show you smart solution for that problem in my next article about that subject In memory data grid with Hazelcast.
