Preface
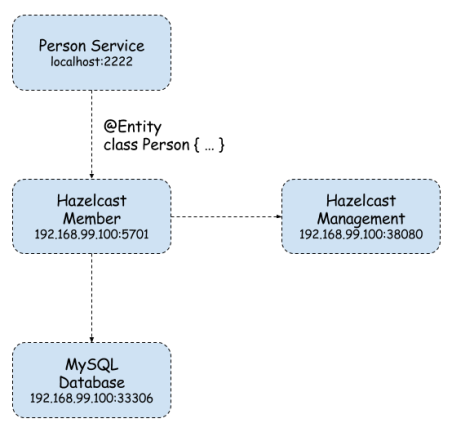
In-Memory Data Grid is an in-memory distributed key-value store that enables caching data using distributed clusters. Do not confuse this solution with in-memory or nosql database. In most cases it is used for performance reasons – all data is stored in RAM not in the disk like in traditional databases. For the first time I had a touch with in-memory data grid while we considering moving to Oracle Coherence in one of organizations I had been working before. The solution really made me curious. Oracle Coherence is obviously a paid solution, but there are also some open source solutions among which the most interesting seem to be Apache Ignite and Hazelcast. Today I’m going to show you how to use Hazelcast for caching data stored in MySQL database accessed by Spring Data DAO objects. Here’s the figure illustrating architecture of presented solution.
Implementation
-
Starting Docker containers
We use three Docker containers. First with MySQL database, second with Hazelcast instance and third for Hazelcast Management Center – UI dashboard for monitoring Hazelcast cluster instances.
docker run -d --name mysql -p 33306:3306 mysql
docker run -d --name hazelcast -p 5701:5701 hazelcast/hazelcast
docker run -d --name hazelcast-mgmt -p 38080:8080 hazelcast/management-center:latest
If we would like to connect with Hazelcast Management Center from Hazelcast instance we need to place custom hazelcast.xml in /opt/hazelcast catalog inside Docker container. This can be done in two ways, by extending hazelcast base image or just by copying file to existing hazelcast container and restarting it.
docker run -d --name hazelcast -p 5701:5701 hazelcast/hazelcast
docker stop hazelcast
docker start hazelcast
Here’s the most important Hazelcast’s configuration file fragment.
<hazelcast xmlns="http://www.hazelcast.com/schema/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.hazelcast.com/schema/config http://www.hazelcast.com/schema/config/hazelcast-config-3.8.xsd">
<group>
<name>dev</name>
<password>dev-pass</password>
</group>
<management-center enabled="true" update-interval="3">http://192.168.99.100:38080/mancenter</management-center>
...
</hazelcast>
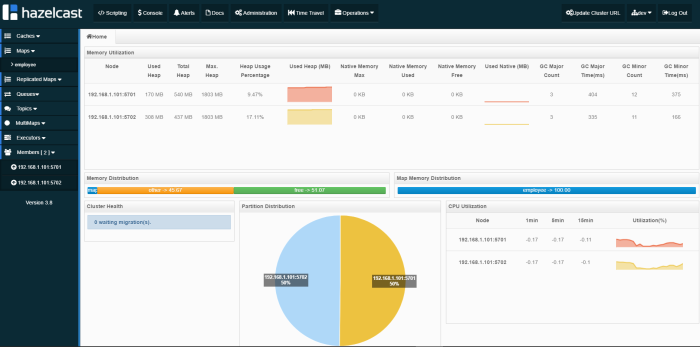
Hazelcast Dashboard is available under http://192.168.99.100:38080/mancenter address. We can monitor there all running cluster members, maps and some other parameters.
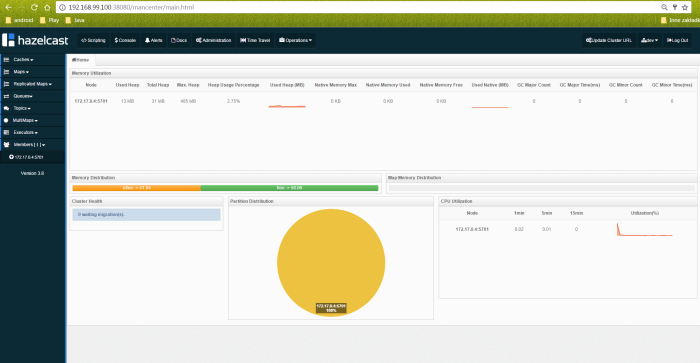
Project is based on Spring Boot 1.5.3.RELEASE. We also need to add Spring Web and MySQL Java connector dependencies. Here’s root project pom.xml.
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.3.RELEASE</version>
</parent>
...
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
...
</dependencies>
Inside person-service module we declared some other dependencies to Hazelcast artifacts and Spring Data JPA. I had to override managed hibernate-core version for Spring Boot 1.5.3.RELEASE, because Hazelcast didn’t worked properly with 5.0.12.Final. Hazelcast needs hibernate-core in 5.0.9.Final version. Otherwise, an exception occurs when starting application.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-client</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-hibernate5</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.0.9.Final</version>
</dependency>
</dependencies>
-
Hibernate Cache configuration
Probably you can configure it in several different ways, but for me the most suitable solution was inside application.yml. Here’s YAML configurarion file fragment. I enabled L2 Hibernate cache, set Hazelcast native client address, credentials and cache factory class HazelcastCacheRegionFactory. We can also set HazelcastLocalCacheRegionFactory. The differences between them are in performance – local factory is faster since its operations are handled as distributed calls. While if you use HazelcastCacheRegionFactory, you can see your maps on Management Center.
spring:
application:
name: person-service
datasource:
url: jdbc:mysql://192.168.99.100:33306/datagrid?useSSL=false
username: datagrid
password: datagrid
jpa:
properties:
hibernate:
show_sql: true
cache:
use_query_cache: true
use_second_level_cache: true
hazelcast:
use_native_client: true
native_client_address: 192.168.99.100:5701
native_client_group: dev
native_client_password: dev-pass
region:
factory_class: com.hazelcast.hibernate.HazelcastCacheRegionFactory
First, we need to enable caching for Person @Entity.
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
@Entity
public class Person implements Serializable {
private static final long serialVersionUID = 3214253910554454648L;
@Id
@GeneratedValue
private Integer id;
private String firstName;
private String lastName;
private String pesel;
private int age;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getPesel() {
return pesel;
}
public void setPesel(String pesel) {
this.pesel = pesel;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [id=" + id + ", firstName=" + firstName + ", lastName=" + lastName + ", pesel=" + pesel + "]";
}
}
DAO is implemented using Spring Data CrudRepository. Sample application source code is available on GitHub.
public interface PersonRepository extends CrudRepository<Person, Integer> {
public List<Person> findByPesel(String pesel);
}
Testing
Let’s insert a little more data to the table. You can use my AddPersonRepositoryTest for that. It will insert 1M rows into the person table. Finally, we can call enpoint http://localhost:2222/persons/{id} twice with the same id. For me, it looks like below: 22ms for first call, 3ms for next call which is read from L2 cache. Entity can be cached only by primary key. If you call http://localhost:2222/persons/pesel/{pesel} entity will always be searched bypassing the L2 cache.
2017-05-05 17:07:27.360 DEBUG 9164 --- [nio-2222-exec-9] org.hibernate.SQL : select person0_.id as id1_0_0_, person0_.age as age2_0_0_, person0_.first_name as first_na3_0_0_, person0_.last_name as last_nam4_0_0_, person0_.pesel as pesel5_0_0_ from person person0_ where person0_.id=?
Hibernate: select person0_.id as id1_0_0_, person0_.age as age2_0_0_, person0_.first_name as first_na3_0_0_, person0_.last_name as last_nam4_0_0_, person0_.pesel as pesel5_0_0_ from person person0_ where person0_.id=?
2017-05-05 17:07:27.362 DEBUG 9164 --- [nio-2222-exec-9] o.h.l.p.e.p.i.ResultSetProcessorImpl : Starting ResultSet row #0
2017-05-05 17:07:27.362 DEBUG 9164 --- [nio-2222-exec-9] l.p.e.p.i.EntityReferenceInitializerImpl : On call to EntityIdentifierReaderImpl#resolve, EntityKey was already known; should only happen on root returns with an optional identifier specified
2017-05-05 17:07:27.363 DEBUG 9164 --- [nio-2222-exec-9] o.h.engine.internal.TwoPhaseLoad : Resolving associations for [pl.piomin.services.datagrid.person.model.Person#444]
2017-05-05 17:07:27.364 DEBUG 9164 --- [nio-2222-exec-9] o.h.engine.internal.TwoPhaseLoad : Adding entity to second-level cache: [pl.piomin.services.datagrid.person.model.Person#444]
2017-05-05 17:07:27.373 DEBUG 9164 --- [nio-2222-exec-9] o.h.engine.internal.TwoPhaseLoad : Done materializing entity [pl.piomin.services.datagrid.person.model.Person#444]
2017-05-05 17:07:27.373 DEBUG 9164 --- [nio-2222-exec-9] o.h.r.j.i.ResourceRegistryStandardImpl : HHH000387: ResultSet's statement was not registered
2017-05-05 17:07:27.374 DEBUG 9164 --- [nio-2222-exec-9] .l.e.p.AbstractLoadPlanBasedEntityLoader : Done entity load : pl.piomin.services.datagrid.person.model.Person#444
2017-05-05 17:07:27.374 DEBUG 9164 --- [nio-2222-exec-9] o.h.e.t.internal.TransactionImpl : committing
2017-05-05 17:07:30.168 DEBUG 9164 --- [nio-2222-exec-6] o.h.e.t.internal.TransactionImpl : begin
2017-05-05 17:07:30.171 DEBUG 9164 --- [nio-2222-exec-6] o.h.e.t.internal.TransactionImpl : committing
Query Cache
We can enable JPA query caching by marking repository method with @Cacheable annotation and adding @EnableCaching to main class definition.
public interface PersonRepository extends CrudRepository<Person, Integer> {
@Cacheable("findByPesel")
public List<Person> findByPesel(String pesel);
}
In addition to the @EnableCaching annotation we should declare HazelcastIntance and CacheManager beans. As a cache manager HazelcastCacheManager from hazelcast-spring library is used.
@SpringBootApplication
@EnableCaching
public class PersonApplication {
public static void main(String[] args) {
SpringApplication.run(PersonApplication.class, args);
}
@Bean
HazelcastInstance hazelcastInstance() {
ClientConfig config = new ClientConfig();
config.getGroupConfig().setName("dev").setPassword("dev-pass");
config.getNetworkConfig().addAddress("192.168.99.100");
config.setInstanceName("cache-1");
HazelcastInstance instance = HazelcastClient.newHazelcastClient(config);
return instance;
}
@Bean
CacheManager cacheManager() {
return new HazelcastCacheManager(hazelcastInstance());
}
}
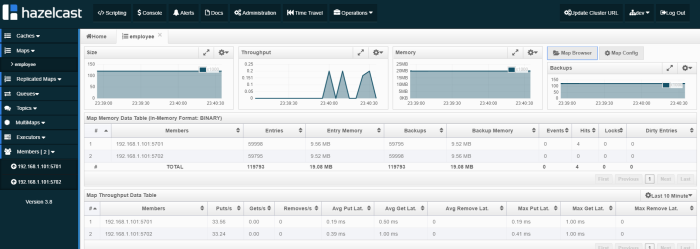
Now, we should try find person by PESEL number by calling endpoint http://localhost:2222/persons/pesel/{pesel}. Cached query is stored as a map as you see in the picture below.
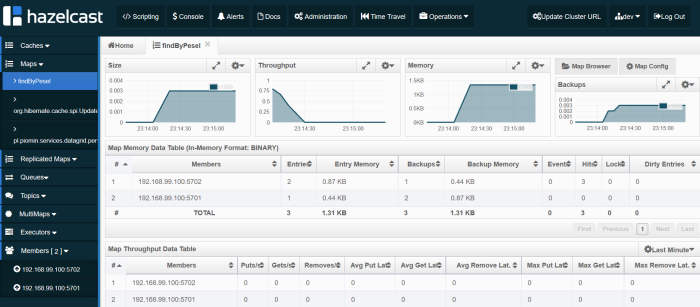
Clustering
Before final words let me say a little about clustering, what is the key functionality of Hazelcast in memory data grid. In the previous chapters we based on single Hazelcast instance. Let’s begin from running second container with Hazelcast exposed on different port.
docker run -d --name hazelcast2 -p 5702:5701 hazelcast/hazelcast
Now we should perform one change in hazelcast.xml configuration file. Because data grid is ran inside docker container the public address has to be set. For the first container it is 192.168.99.100:5701, and for second 192.168.99.100:5702, because it is exposed on 5702 port.
<network>
...
<public-address>192.168.99.100:5701</public-address>
...
</network>
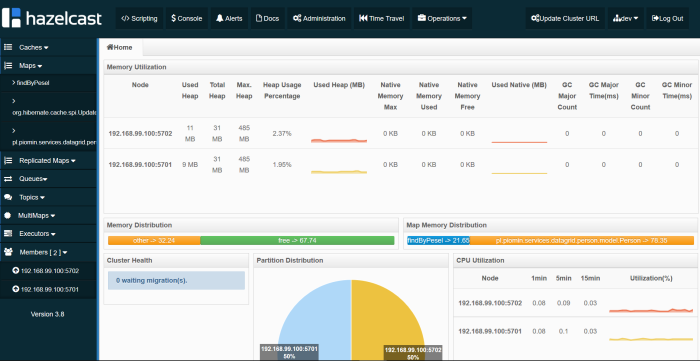
When starting person-service application you should see in the logs similar to visible below – connection with two cluster members.
Members [2] {
Member [192.168.99.100]:5702 - 04f790bc-6c2d-4c21-ba8f-7761a4a7422c
Member [192.168.99.100]:5701 - 2ca6e30d-a8a7-46f7-b1fa-37921aaa0e6b
}
All Hazelcast running instances are visible in Management Center.
Conclusion
Caching and clustering with Hazelcast are simple and fast. We can cache JPA entities and queries. Monitoring is realized via Hazelcast Management Center dashboard. One problem for me is that I’m able to cache entities only by primary key. If I would like to find entity by other index like PESEL number I had to cache findByPesel query. Even if entity was cached before by id query will not find it in the cache but perform SQL on database. Only next query call is cached. I’ll show you smart solution for that problem in my next article about that subject In memory data grid with Hazelcast.