In this guide I’m going to discuss some more advanced topics related to GraphQL and databases, like filtering or relationship fetching. Of course, before proceeding to the more advanced issues I will take a moment to describe the basics – something you can found in many other articles. If you already had the opportunity to familiarize yourself with the concept over GraphQL you may have some questions. Probably one of them is: “Ok. It’s nice. But what if I would like to use GraphQL in the real application that connects to database and provides API for more advanced queries?”. If that is your main question, my current article is definitely for you. If you are thinking about using GraphQL in your microservices architecture you may also refer to my previous article GraphQL – The Future of Microservices?. Continue reading “An Advanced Guide to GraphQL with Spring Boot”
Tag: graphiql
GraphQL – The Future of Microservices?
Often, GraphQL is presented as a revolutionary way of designing web APIs in comparison to REST. However, if you would take a closer look on that technology you will see that there are so many differences between them. GraphQL is a relatively new solution that has been open sourced by Facebook in 2015. Today, REST is still the most popular paradigm used for exposing APIs and inter-service communication between microservices. Is GraphQL going to overtake REST in the future? Let’s take a look how to create microservices communicating through GraphQL API using Spring Boot and Apollo client.
Let’s begin from an architecture of our sample system. We have three microservices that communicates to each other using URLs taken from Eureka service discovery.
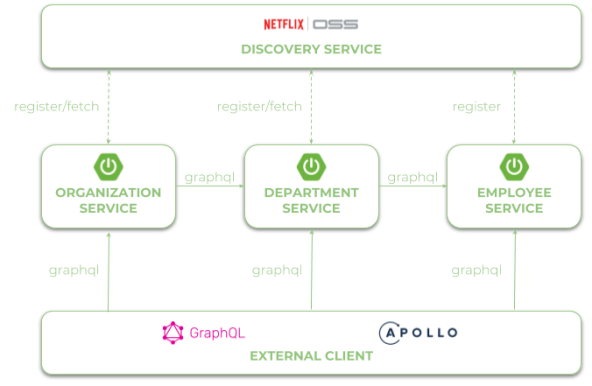
1. Enabling Spring Boot support for GraphQL
We can easily enable support for GraphQL on the server-side Spring Boot application just by including some starters. After including graphql-spring-boot-starter the GraphQL servlet would be automatically accessible under path /graphql. We can override that default path by settings property graphql.servlet.mapping in application.yml file. We should also enable GraphiQL – an in-browser IDE for writing, validating, and testing GraphQL queries, and GraphQL Java Tools library, which contains useful components for creating queries and mutations. Thanks to that library any files on the classpath with .graphqls extension will be used to provide the schema definition.
<dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.3</version> </dependency>
2. Building GraphQL schema definition
Every schema definitions contains data types declaration, relationships between them, and a set of operations including queries for searching objects and mutations for creating, updating or deleting data. Usually we will start from creating type declaration, which is responsible for domain object definition. You can specify if the field is required using ! char or if it is an array using [...]. Definition has to contain type declaration or reference to other types available in the specification.
type Employee {
id: ID!
organizationId: Int!
departmentId: Int!
name: String!
age: Int!
position: String!
salary: Int!
}
Here’s an equivalent Java class to GraphQL definition visible above. GraphQL type Int can be also mapped to Java Long. The ID scalar type represents a unique identifier – in that case it also would be Java Long.
public class Employee {
private Long id;
private Long organizationId;
private Long departmentId;
private String name;
private int age;
private String position;
private int salary;
// constructor
// getters
// setters
}
The next part of schema definition contains queries and mutations declaration. Most of the queries return list of objects – what is marked with [Employee]. Inside EmployeeQueries type we have declared all find methods, while inside EmployeeMutations type methods for adding, updating and removing employees. If you pass the whole object to that method you need to declare it as an input type.
schema {
query: EmployeeQueries
mutation: EmployeeMutations
}
type EmployeeQueries {
employees: [Employee]
employee(id: ID!): Employee!
employeesByOrganization(organizationId: Int!): [Employee]
employeesByDepartment(departmentId: Int!): [Employee]
}
type EmployeeMutations {
newEmployee(employee: EmployeeInput!): Employee
deleteEmployee(id: ID!) : Boolean
updateEmployee(id: ID!, employee: EmployeeInput!): Employee
}
input EmployeeInput {
organizationId: Int
departmentId: Int
name: String
age: Int
position: String
salary: Int
}
3. Queries and mutation implementation
Thanks to GraphQL Java Tools and Spring Boot GraphQL auto-configuration we don’t need to do much to implement queries and mutations in our application. The EmployeesQuery bean has to GraphQLQueryResolver interface. Basing on that Spring would be able to automatically detect and call right method as a response to one of the GraphQL query declared inside the schema. Here’s a class containing an implementation of queries.
@Component
public class EmployeeQueries implements GraphQLQueryResolver {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeQueries.class);
@Autowired
EmployeeRepository repository;
public List employees() {
LOGGER.info("Employees find");
return repository.findAll();
}
public List employeesByOrganization(Long organizationId) {
LOGGER.info("Employees find: organizationId={}", organizationId);
return repository.findByOrganization(organizationId);
}
public List employeesByDepartment(Long departmentId) {
LOGGER.info("Employees find: departmentId={}", departmentId);
return repository.findByDepartment(departmentId);
}
public Employee employee(Long id) {
LOGGER.info("Employee find: id={}", id);
return repository.findById(id);
}
}
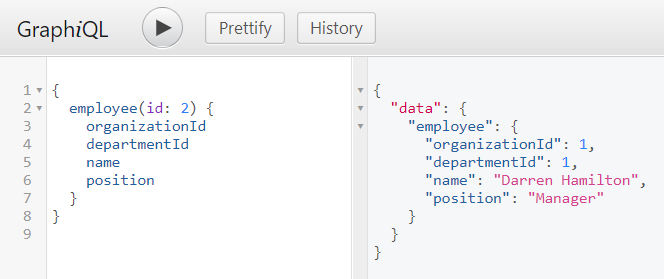
If you would like to call, for example method employee(Long id) you should build the following query. You can easily test it in your application using GraphiQL tool available under path /graphiql.
The bean responsible for implementation of mutation methods needs to implement GraphQLMutationResolver. Despite declaration of EmployeeInput we still to use the same domain object as returned by queries – Employee.
@Component
public class EmployeeMutations implements GraphQLMutationResolver {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeQueries.class);
@Autowired
EmployeeRepository repository;
public Employee newEmployee(Employee employee) {
LOGGER.info("Employee add: employee={}", employee);
return repository.add(employee);
}
public boolean deleteEmployee(Long id) {
LOGGER.info("Employee delete: id={}", id);
return repository.delete(id);
}
public Employee updateEmployee(Long id, Employee employee) {
LOGGER.info("Employee update: id={}, employee={}", id, employee);
return repository.update(id, employee);
}
}
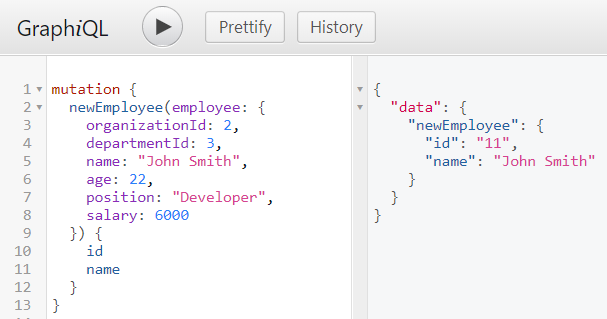
We can also use GraphiQL to test mutations. Here’s the command that adds new employee, and receives response with employee’s id and name.
4. Generating client-side classes
Ok, we have successfully created server-side application. We have already tested some queries using GraphiQL. But our main goal is to create some other microservices that communicate with employee-service application through GraphQL API. Here the most of tutorials about Spring Boot and GraphQL ending.
To be able to communicate with our first application through GraphQL API we have two choices. We can get a standard REST client and implement GraphQL API by ourselves with HTTP GET requests or use one of existing Java clients. Surprisingly, there are no many GraphQL Java client implementations available. The most serious choice is Apollo GraphQL Client for Android. Of course it is not designed only for Android devices, and you can successfully use it in your microservice Java application.
Before using the client we need to generate classes from schema and .grapql files. The recommended way to do it is through Apollo Gradle Plugin. There are also some Maven plugins, but none of them provide the level of automation as Gradle plugin, for example it automatically downloads node.js required for generating client-side classes. So, the first step is to add Apollo plugin and runtime to the project dependencies.
buildscript {
repositories {
jcenter()
maven { url 'https://oss.sonatype.org/content/repositories/snapshots/' }
}
dependencies {
classpath 'com.apollographql.apollo:apollo-gradle-plugin:1.0.1-SNAPSHOT'
}
}
apply plugin: 'com.apollographql.android'
dependencies {
compile 'com.apollographql.apollo:apollo-runtime:1.0.1-SNAPSHOT'
}
GraphQL Gradle plugin tries to find files with .graphql extension and schema.json inside src/main/graphql directory. GraphQL JSON schema can be obtained from your Spring Boot application by calling resource /graphql/schema.json. File .graphql contains queries definition. Query employeesByOrganization will be called by organization-service, while employeesByDepartment by both department-service and organization-service. Those two application needs a little different set of data in the response. Application department-service requires more detailed information about every employee than organization-service. GraphQL is an excellent solution in that case, because we can define the require set of data in the response on the client side. Here’s query definition of employeesByOrganization called by organization-service.
query EmployeesByOrganization($organizationId: Int!) {
employeesByOrganization(organizationId: $organizationId) {
id
name
}
}
Application organization-service would also call employeesByDepartment query.
query EmployeesByDepartment($departmentId: Int!) {
employeesByDepartment(departmentId: $departmentId) {
id
name
}
}
The query employeesByDepartment is also called by department-service, which requires not only id and name fields, but also position and salary.
query EmployeesByDepartment($departmentId: Int!) {
employeesByDepartment(departmentId: $departmentId) {
id
name
position
salary
}
}
All the generated classes are available under build/generated/source/apollo directory.
5. Building Apollo client with discovery
After generating all required classes and including them into calling microservices we may proceed to the client implementation. Apollo client has two important features that will affect our development:
- It provides only asynchronous methods based on callback
- It does not integrate with service discovery based on Spring Cloud Netflix Eureka
Here’s an implementation of employee-service client inside department-service. I used EurekaClient directly (1). It gets all running instances registered as EMPLOYEE-SERVICE. Then it selects one instance form the list of available instances randomly (2). The port number of that instance is passed to ApolloClient (3). Before calling asynchronous method enqueue provided by ApolloClient we create lock (4), which waits max. 5 seconds for releasing (8). Method enqueue returns response in the callback method onResponse (5). We map the response body from GraphQL Employee object to returned object (6) and then release the lock (7).
@Component
public class EmployeeClient {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeClient.class);
private static final int TIMEOUT = 5000;
private static final String SERVICE_NAME = "EMPLOYEE-SERVICE";
private static final String SERVER_URL = "http://localhost:%d/graphql";
Random r = new Random();
@Autowired
private EurekaClient discoveryClient; // (1)
public List findByDepartment(Long departmentId) throws InterruptedException {
List employees = new ArrayList();
Application app = discoveryClient.getApplication(SERVICE_NAME); // (2)
InstanceInfo ii = app.getInstances().get(r.nextInt(app.size()));
ApolloClient client = ApolloClient.builder().serverUrl(String.format(SERVER_URL, ii.getPort())).build(); // (3)
CountDownLatch lock = new CountDownLatch(1); // (4)
client.query(EmployeesByDepartmentQuery.builder().build()).enqueue(new Callback() {
@Override
public void onFailure(ApolloException ex) {
LOGGER.info("Err: {}", ex);
lock.countDown();
}
@Override
public void onResponse(Response res) { // (5)
LOGGER.info("Res: {}", res);
employees.addAll(res.data().employees().stream().map(emp -> new Employee(Long.valueOf(emp.id()), emp.name(), emp.position(), emp.salary())).collect(Collectors.toList())); // (6)
lock.countDown(); // (7)
}
});
lock.await(TIMEOUT, TimeUnit.MILLISECONDS); // (8)
return employees;
}
}
Finally, EmployeeClient is injected into the query resolver class – DepartmentQueries, and used inside query departmentsByOrganizationWithEmployees.
@Component
public class DepartmentQueries implements GraphQLQueryResolver {
private static final Logger LOGGER = LoggerFactory.getLogger(DepartmentQueries.class);
@Autowired
EmployeeClient employeeClient;
@Autowired
DepartmentRepository repository;
public List departmentsByOrganizationWithEmployees(Long organizationId) {
LOGGER.info("Departments find: organizationId={}", organizationId);
List departments = repository.findByOrganization(organizationId);
departments.forEach(d -> {
try {
d.setEmployees(employeeClient.findByDepartment(d.getId()));
} catch (InterruptedException e) {
LOGGER.error("Error calling employee-service", e);
}
});
return departments;
}
// other queries
}
Before calling target query we should take a look on the schema created for department-service. Every Department object can contain the list of assigned employees, so we also define type Employee referenced by Department type.
schema {
query: DepartmentQueries
mutation: DepartmentMutations
}
type DepartmentQueries {
departments: [Department]
department(id: ID!): Department!
departmentsByOrganization(organizationId: Int!): [Department]
departmentsByOrganizationWithEmployees(organizationId: Int!): [Department]
}
type DepartmentMutations {
newDepartment(department: DepartmentInput!): Department
deleteDepartment(id: ID!) : Boolean
updateDepartment(id: ID!, department: DepartmentInput!): Department
}
input DepartmentInput {
organizationId: Int!
name: String!
}
type Department {
id: ID!
organizationId: Int!
name: String!
employees: [Employee]
}
type Employee {
id: ID!
name: String!
position: String!
salary: Int!
}
Now, we can call our test query with list of required fields using GraphiQL. An application department-service is by default available under port 8091, so we may call it using address http://localhost:8091/graphiql.

Conclusion
GraphQL seems to be an interesting alternative to standard REST APIs. However, we should not consider it as a replacement to REST. There are some use cases where GraphQL may be better choice, and some use cases where REST is better choice. If your clients does not need the full set of fields returned by the server side, and moreover you have many clients with different requirements to the single endpoint – GraphQL is a good choice. When it comes to microservices there are no solutions based on Java that allow you to use GraphQL together with service discovery, load balancing or API gateway out-of-the-box. In this article I have shown an example of usage Apollo GraphQL client together with Spring Cloud Eureka for inter-service communication. Sample applications source code is available on GitHub https://github.com/piomin/sample-graphql-microservices.git.
