Consumer Driven Contract (CDC) testing is one of the method that allows you to verify integration between applications within your system. The number of such interactions may be really large especially if you maintain microservices-based architecture. Assuming that every microservice is developed by different teams or sometimes even different vendors, it is important to automate the whole testing process. As usual, we can use Jenkins server for running contract tests within our Continuous Integration (CI) process.
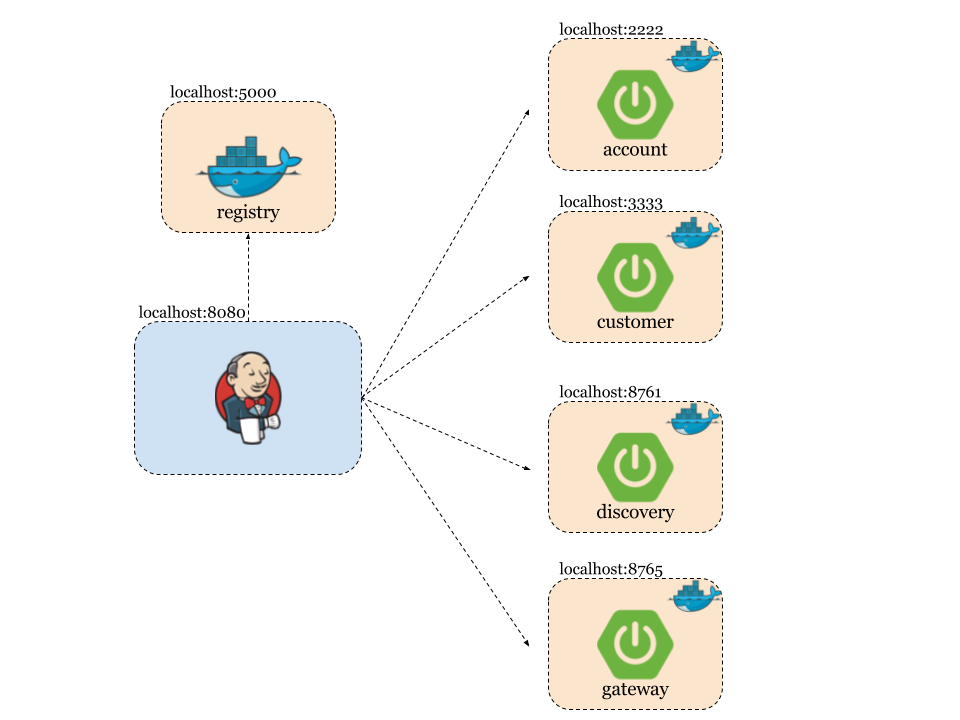
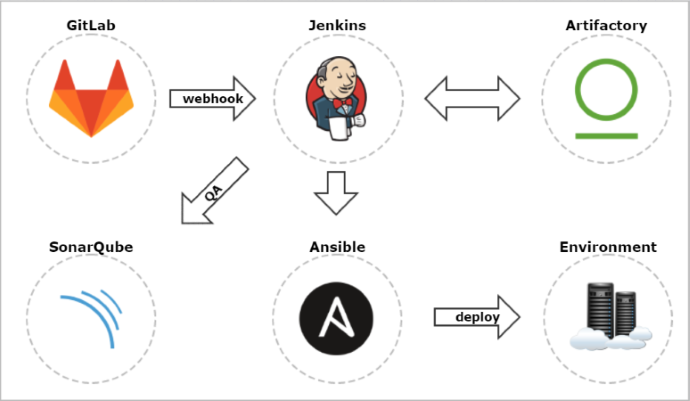
The sample scenario has been visualized on the picture below. We have one application (person-service) that exposes API leveraged by three different applications. Each application is implementing by a different development team. Consequently, every application is stored in the separated Git repository and has dedicated pipeline in Jenkins for building, testing and deploying.
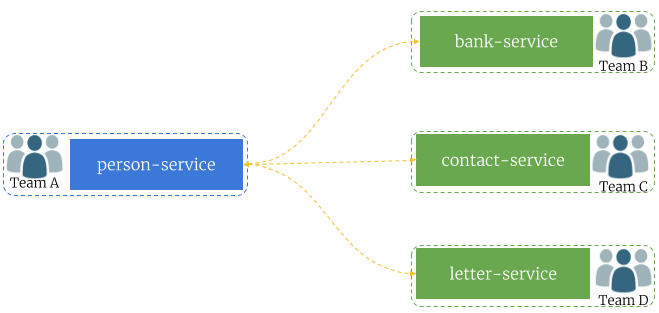
The source code of sample applications is available on GitHub in the repository sample-spring-cloud-contract-ci (https://github.com/piomin/sample-spring-cloud-contract-ci.git). I placed all the sample microservices in the single Git repository only for our demo simplification. We will still treat them as a separated microservices, developed and built independently.
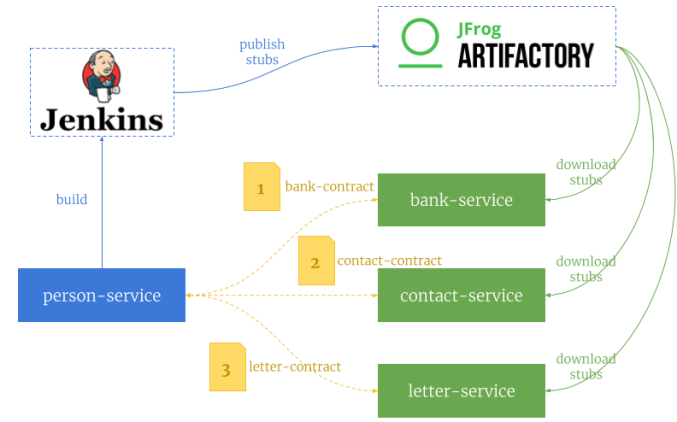
In this article I used Spring Cloud Contract for CDC implementation. It is the first choice solution for JVM applications written in Spring Boot. Contracts can be defined using Groovy or YAML notation. After building on the producer side Spring Cloud Contract generate special JAR file with stubs suffix, that contains all defined contracts and JSON mappings. Such a JAR file can be build on Jenkins and then published on Artifactory. Contract consumer also use the same Artifactory server, so they can use the latest version of stubs file. Because every application expects different response from person-service, we have to define three different contracts between person-service and a target consumer.
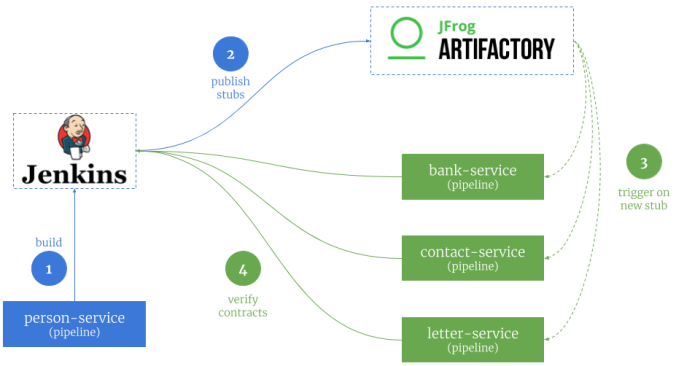
Let’s analyze the sample scenario. Assuming we have performed some changes in the API exposed by person-service and we have modified contracts on the producer side, we would like to publish them on shared server. First, we need to verify contracts against producer (1), and in case of success publish artifact with stubs to Artifactory (2). All the pipelines defined for applications that use this contract are able to trigger the build on a new version of JAR file with stubs (3). Then, the newest version contract is verifying against consumer (4). If contract testing fails, pipeline is able to notify the responsible team about this failure.
1. Pre-requirements
Before implementing and running any sample we need to prepare our environment. We need to launch Jenkins and Artifactory servers on the local machine. The most suitable way for this is through a Docker containers. Here are the commands required for run these containers.
$ docker run --name artifactory -d -p 8081:8081 docker.bintray.io/jfrog/artifactory-oss:latest
$ docker run --name jenkins -d -p 8080:8080 -p 50000:50000 jenkins/jenkins:lts
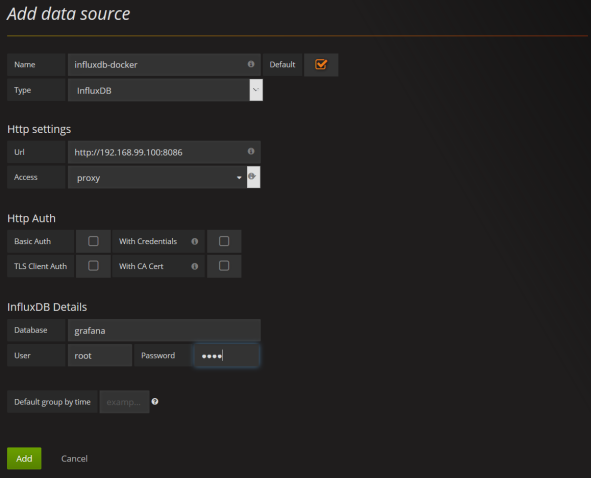
I don’t know if you are familiar with such tools like Artifactory and Jenkins. But after starting them we need to configure some things. First you need to initialize Maven repositories for Artifactory. You will be prompt for that just after a first launch. It also automatically add one remote repository: JCenter Bintray (https://bintray.com/bintray/jcenter), which is enough for our build. Jenkins also comes with default set of plugins, which you can install just after first launch (Install suggested plugins). For this demo, you will also have to install plugin for integration with Artifactory (https://wiki.jenkins.io/display/JENKINS/Artifactory+Plugin). If you need more details about Jenkins and Artifactory configuration you can refer to my older article How to setup Continuous Delivery environment.
2. Building contracts
We are beginning contract definition from the producer side application. Producer exposes only one GET /persons/{id} method that returns Person object. Here are the fields contained by Person class.
public class Person {
private Integer id;
private String firstName;
private String lastName;
@JsonFormat(pattern = "yyyy-MM-dd")
private Date birthDate;
private Gender gender;
private Contact contact;
private Address address;
private String accountNo;
// ...
}
The following picture illustrates, which fields of Person object are used by consumers. As you see, some of the fields are shared between consumers, while some other are required only by single consuming application.

Now we can take a look on contract definition between person-service and bank-service.
import org.springframework.cloud.contract.spec.Contract
Contract.make {
request {
method 'GET'
urlPath('/persons/1')
}
response {
status OK()
body([
id: 1,
firstName: 'Piotr',
lastName: 'Minkowski',
gender: $(regex('(MALE|FEMALE)')),
contact: ([
email: $(regex(email())),
phoneNo: $(regex('[0-9]{9}$'))
])
])
headers {
contentType(applicationJson())
}
}
}
For comparison, here’s definition of contract between person-service and letter-service.
import org.springframework.cloud.contract.spec.Contract
Contract.make {
request {
method 'GET'
urlPath('/persons/1')
}
response {
status OK()
body([
id: 1,
firstName: 'Piotr',
lastName: 'Minkowski',
address: ([
city: $(regex(alphaNumeric())),
country: $(regex(alphaNumeric())),
postalCode: $(regex('[0-9]{2}-[0-9]{3}')),
houseNo: $(regex(positiveInt())),
street: $(regex(nonEmpty()))
])
])
headers {
contentType(applicationJson())
}
}
}
3. Implementing tests on the producer side
Ok, we have three different contracts assigned to the single endpoint exposed by person-service. We need to publish them in such a way to that they are easily available for consumers. In that case Spring Cloud Contract comes with a handy solution. We may define contracts with different response for the same request, and than choose the appropriate definition on the consumer side. All those contract definitions will be published within the same JAR file. Because we have three consumers we define three different contracts placed in directories bank-consumer, contact-consumer and letter-consumer.
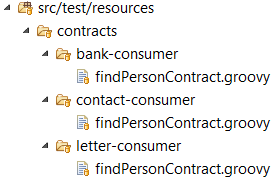
All the contracts will use a single base test class. To achieve it we need to provide a fully qualified name of that class for Spring Cloud Contract Verifier plugin in pom.xml.
<plugin>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-contract-maven-plugin</artifactId>
<extensions>true</extensions>
<configuration>
<baseClassForTests>pl.piomin.services.person.BasePersonContractTest</baseClassForTests>
</configuration>
</plugin>
Here’s the full definition of base class for our contract tests. We will mock the repository bean with the answer matching to the rules created inside contract files.
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = WebEnvironment.DEFINED_PORT)
public abstract class BasePersonContractTest {
@Autowired
WebApplicationContext context;
@MockBean
PersonRepository repository;
@Before
public void setup() {
RestAssuredMockMvc.webAppContextSetup(this.context);
PersonBuilder builder = new PersonBuilder()
.withId(1)
.withFirstName("Piotr")
.withLastName("Minkowski")
.withBirthDate(new Date())
.withAccountNo("1234567890")
.withGender(Gender.MALE)
.withPhoneNo("500070935")
.withCity("Warsaw")
.withCountry("Poland")
.withHouseNo(200)
.withStreet("Al. Jerozolimskie")
.withEmail("piotr.minkowski@gmail.com")
.withPostalCode("02-660");
when(repository.findById(1)).thenReturn(builder.build());
}
}
Spring Cloud Contract Maven plugin visible above is responsible for generating stubs from contract definitions. It is executed during Maven build after running mvn clean install command. The build is performed on Jenkins CI. Jenkins pipeline is responsible for updating remote Git repository, build binaries from source code, running automated tests and finally publishing JAR file containing stubs on a remote artifact repository – Artifactory. Here’s Jenkins pipeline created for the contract producer side (person-service).
node {
withMaven(maven:'M3') {
stage('Checkout') {
git url: 'https://github.com/piomin/sample-spring-cloud-contract-ci.git', credentialsId: 'piomin-github', branch: 'master'
}
stage('Publish') {
def server = Artifactory.server 'artifactory'
def rtMaven = Artifactory.newMavenBuild()
rtMaven.tool = 'M3'
rtMaven.resolver server: server, releaseRepo: 'libs-release', snapshotRepo: 'libs-snapshot'
rtMaven.deployer server: server, releaseRepo: 'libs-release-local', snapshotRepo: 'libs-snapshot-local'
rtMaven.deployer.artifactDeploymentPatterns.addInclude("*stubs*")
def buildInfo = rtMaven.run pom: 'person-service/pom.xml', goals: 'clean install'
rtMaven.deployer.deployArtifacts buildInfo
server.publishBuildInfo buildInfo
}
}
}
We also need to include dependency spring-cloud-starter-contract-verifier to the producer app to enable Spring Cloud Contract Verifier.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-contract-verifier</artifactId>
<scope>test</scope>
</dependency>
4. Implementing tests on the consumer side
To enable Spring Cloud Contract on the consumer side we need to include artifact spring-cloud-starter-contract-stub-runner to the project dependencies.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-contract-stub-runner</artifactId>
<scope>test</scope>
</dependency>
Then, the only thing left is to build JUnit test, which verifies our contract by calling it through OpenFeign client. The configuration of that test is provided inside annotation @AutoConfigureStubRunner. We select the latest version of person-service stubs artifact by setting + in the version section of ids parameter. Because, we have multiple contracts defined inside person-service we need to choose the right for current service by setting consumer-name parameter. All the contract definitions are downloaded from Artifactory server, so we set stubsMode parameter to REMOTE. The address of Artifactory server has to be set using repositoryRoot property.
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = WebEnvironment.NONE)
@AutoConfigureStubRunner(ids = {"pl.piomin.services:person-service:+:stubs:8090"}, consumerName = "letter-consumer", stubsPerConsumer = true, stubsMode = StubsMode.REMOTE, repositoryRoot = "http://192.168.99.100:8081/artifactory/libs-snapshot-local")
@DirtiesContext
public class PersonConsumerContractTest {
@Autowired
private PersonClient personClient;
@Test
public void verifyPerson() {
Person p = personClient.findPersonById(1);
Assert.assertNotNull(p);
Assert.assertEquals(1, p.getId().intValue());
Assert.assertNotNull(p.getFirstName());
Assert.assertNotNull(p.getLastName());
Assert.assertNotNull(p.getAddress());
Assert.assertNotNull(p.getAddress().getCity());
Assert.assertNotNull(p.getAddress().getCountry());
Assert.assertNotNull(p.getAddress().getPostalCode());
Assert.assertNotNull(p.getAddress().getStreet());
Assert.assertNotEquals(0, p.getAddress().getHouseNo());
}
}
Here’s Feign client implementation responsible for calling endpoint exposed by person-service
@FeignClient("person-service")
public interface PersonClient {
@GetMapping("/persons/{id}")
Person findPersonById(@PathVariable("id") Integer id);
}
5. Setup of Continuous Integration process
Ok, we have already defined all the contracts required for our exercise. We have also build a pipeline responsible for building and publishing stubs with contracts on the producer side (person-service). It always publish the newest version of stubs generated from source code. Now, our goal is to launch pipelines defined for three consumer applications, each time when new stubs would be published to Artifactory server by producer pipeline.
The best solution for that would be to trigger a Jenkins build when you deploy an artifact. To achieve it we use Jenkins plugin called URLTrigger, that can be configured to watch for changes on a certain URL, in that case REST API endpoint exposed by Artifactory for selected repository path.
After installing URLTrigger plugin we have to enable it for all consumer pipelines. You can configure it to watch for changes in the returned JSON file from the Artifactory File List REST API, that is accessed via the following URI: http://192.168.99.100:8081/artifactory/api/storage/[PATH_TO_FOLDER_OR_REPO]/. The file maven-metadata.xml will change every time you deploy a new version of application to Artifactory. We can monitor the change of response’s content between the last two polls. The last field that has to be filled is Schedule. If you set it to * * * * * it will poll for a change every minute.
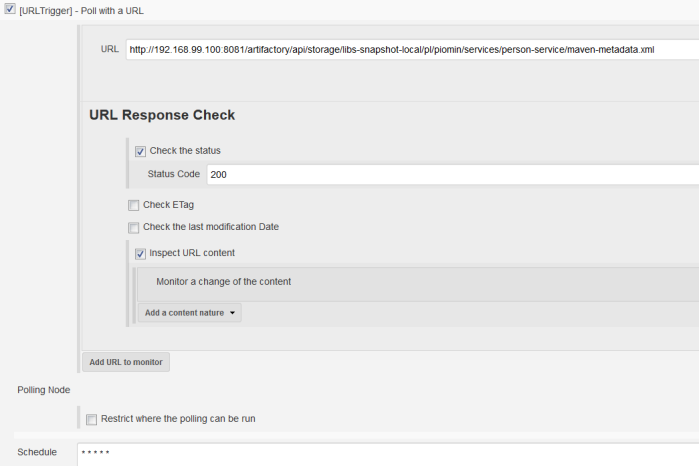
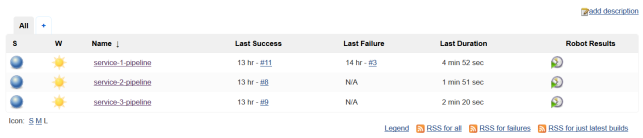
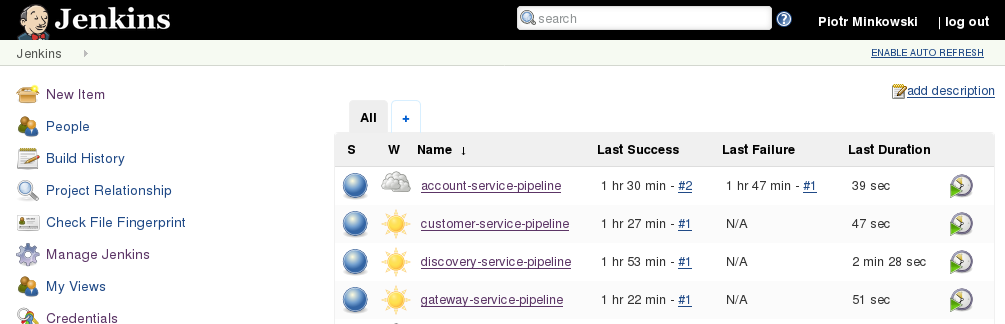
Our three pipelines for consumer applications are ready. The first run was finished with success.

If you have already build person-service application and publish stubs to Artifactory you will see the following structure in libs-snapshot-local repository. I have deployed three different versions of API exposed by person-service. Each time I publish new version of contract all the dependent pipelines are triggered to verify it.
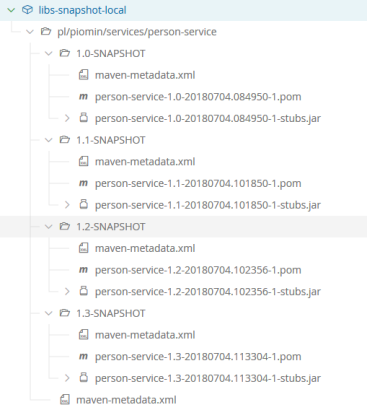
The JAR file with contracts is published under classifier stubs.
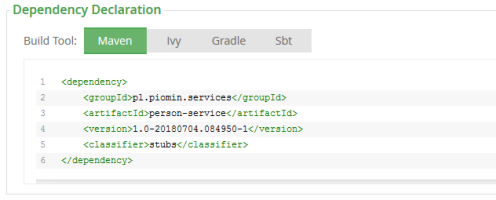
Spring Cloud Contract Stub Runner tries to find the latest version of contracts.
2018-07-04 11:46:53.273 INFO 4185 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Desired version is [+] - will try to resolve the latest version
2018-07-04 11:46:54.752 INFO 4185 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Resolved version is [1.3-SNAPSHOT]
2018-07-04 11:46:54.823 INFO 4185 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Resolved artifact [pl.piomin.services:person-service:jar:stubs:1.3-SNAPSHOT] to /var/jenkins_home/.m2/repository/pl/piomin/services/person-service/1.3-SNAPSHOT/person-service-1.3-SNAPSHOT-stubs.jar
6. Testing change in contract
Ok, we have already prepared contracts and configured our CI environment. Now, let’s perform change in the API exposed by person-service. We will just change the name of one field: accountNo to accountNumber.

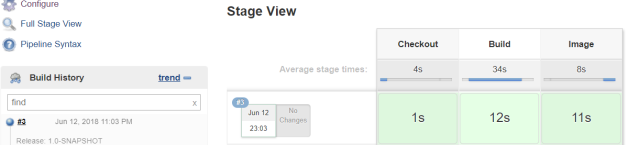
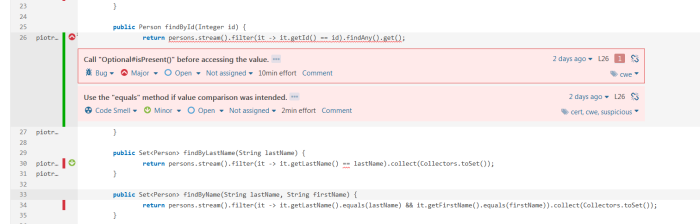
This changes requires a change in contract definition created on the producer side. If you modify the field name there person-service will build successfully and new version of contract will be published to Artifactory. Because all other pipelines listens for changes in the latest version of JAR files with stubs, the build will be started automatically. Microservices letter-service and contact-service do not use field accountNo, so their pipelines will not fail. Only bank-service pipeline report error in contract as shown on the picture below.
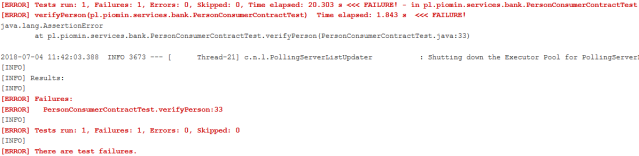
Now, if you were notified about failed verification of the newest contract version between person-service and bank-service, you can perform required change on the consumer side.









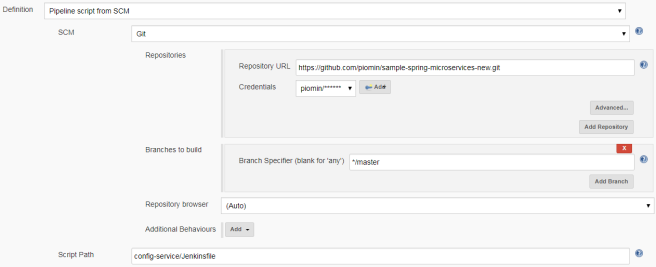

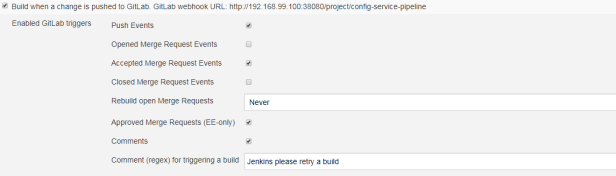
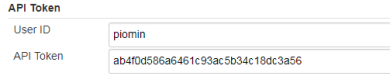
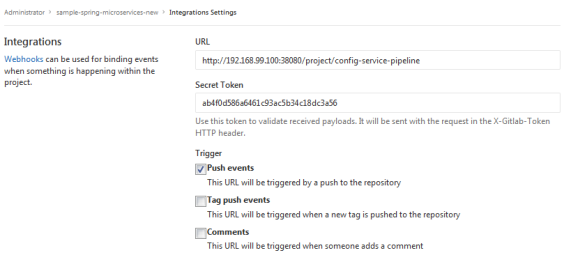





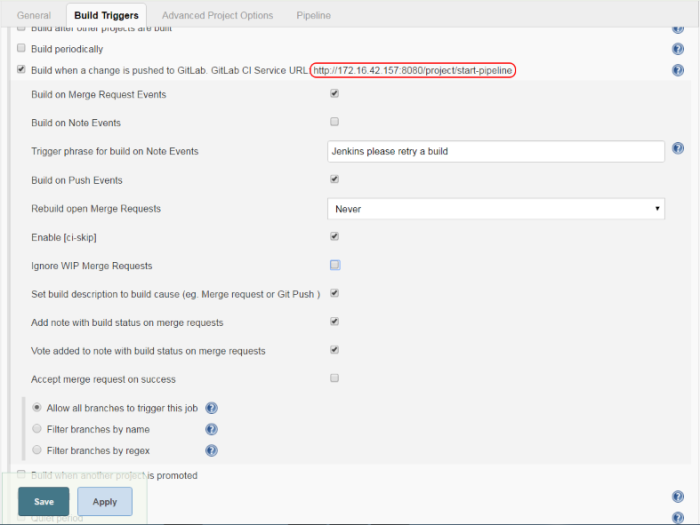
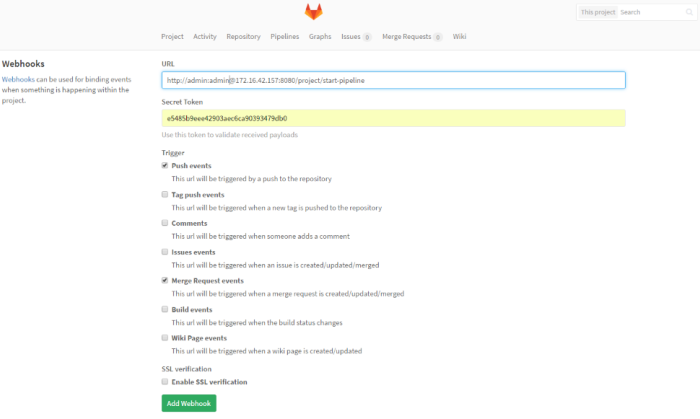 Here’s jenkins pipeline configuration in ‘Build triggers’ section. We have to enable option ‘Build when a change is pushed to GitLab‘. GitLab CI Service URL is the address we have already set in GitLab webhook configuration. There are push and merge request enabled from all branches. It can also be added additional restriction for branch filtering: by name or by regex. To support such kind of trigger in jenkins you need have Gitlab plugin installed.
Here’s jenkins pipeline configuration in ‘Build triggers’ section. We have to enable option ‘Build when a change is pushed to GitLab‘. GitLab CI Service URL is the address we have already set in GitLab webhook configuration. There are push and merge request enabled from all branches. It can also be added additional restriction for branch filtering: by name or by regex. To support such kind of trigger in jenkins you need have Gitlab plugin installed.